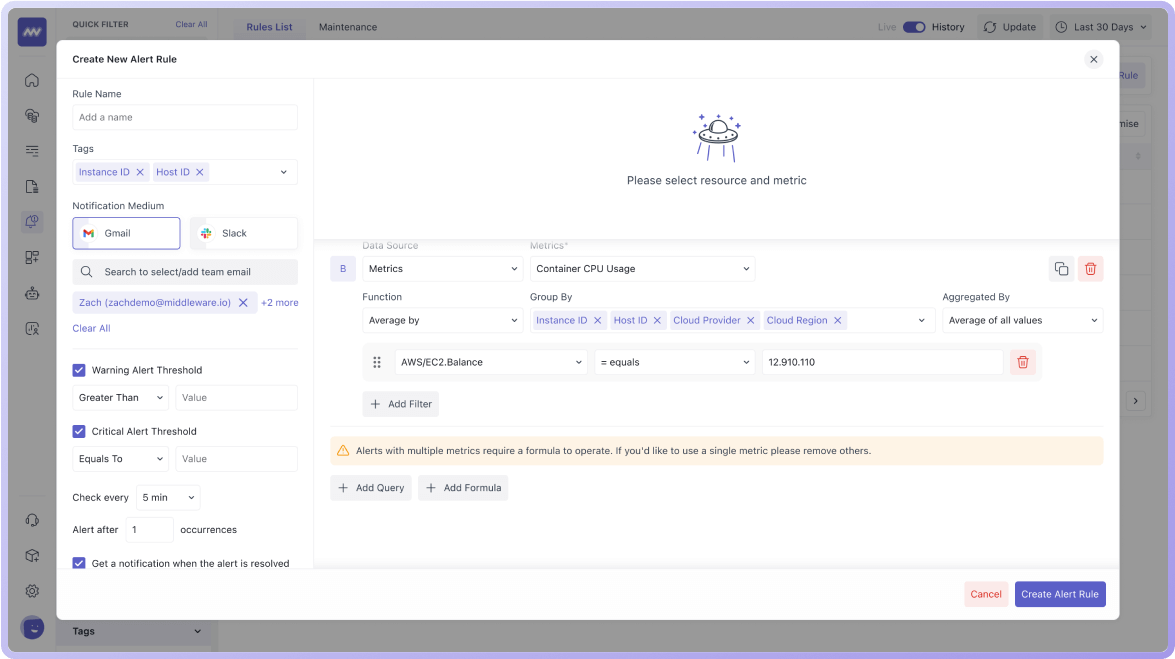
Benefits
Detect, Respond, Resolve
Anomaly & Outlier Detection
Identify unusual patterns and outliers in your system's behavior to detect potential issues.
Dynamic Thresholds
Set adaptive thresholds that adjust to minimize false positives and negatives.
Pre-Configured Default Alerts
Use pre-built alerts for common issues to quickly identify and respond to known problems.
Root Cause Analysis and Correlation
Automatically link related alerts and data to quickly pinpoint the underlying cause of issues.
Multi-Channel Notifications and Alert Allocation
Route alerts to the right teams and channels to ensure prompt attention & effective resolution.
Operate With Precision
Receive timely and targeted alerts to identify and respond to critical issues before they impact your business.
Reduced Downtime and Alert Fatigue
- Identify critical issues before they impact your business.
- Detect anomalies and outliers with machine learning alerts.
- Respond quickly to potential and actual infrastructure errors.
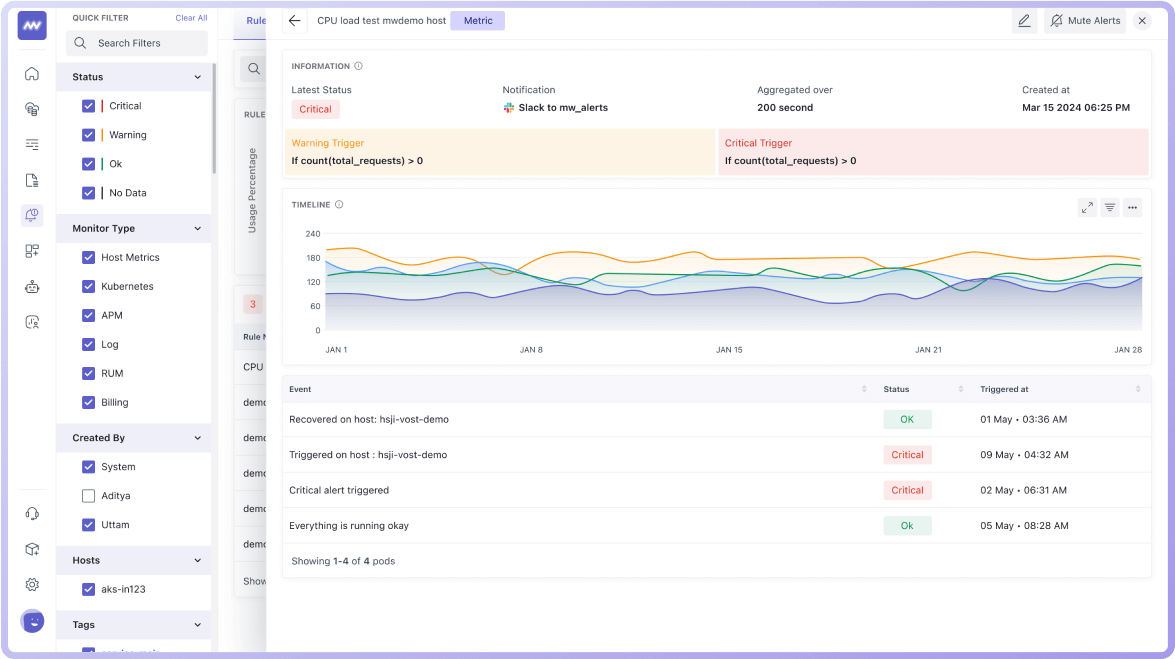
Efficient Root Cause Analysis
- Drill down to related metrics, logs, and data for faster resolution.
- Group anomalies, metrics, and traces to identify root causes.
- View all details related to alerts, including metrics and logs.
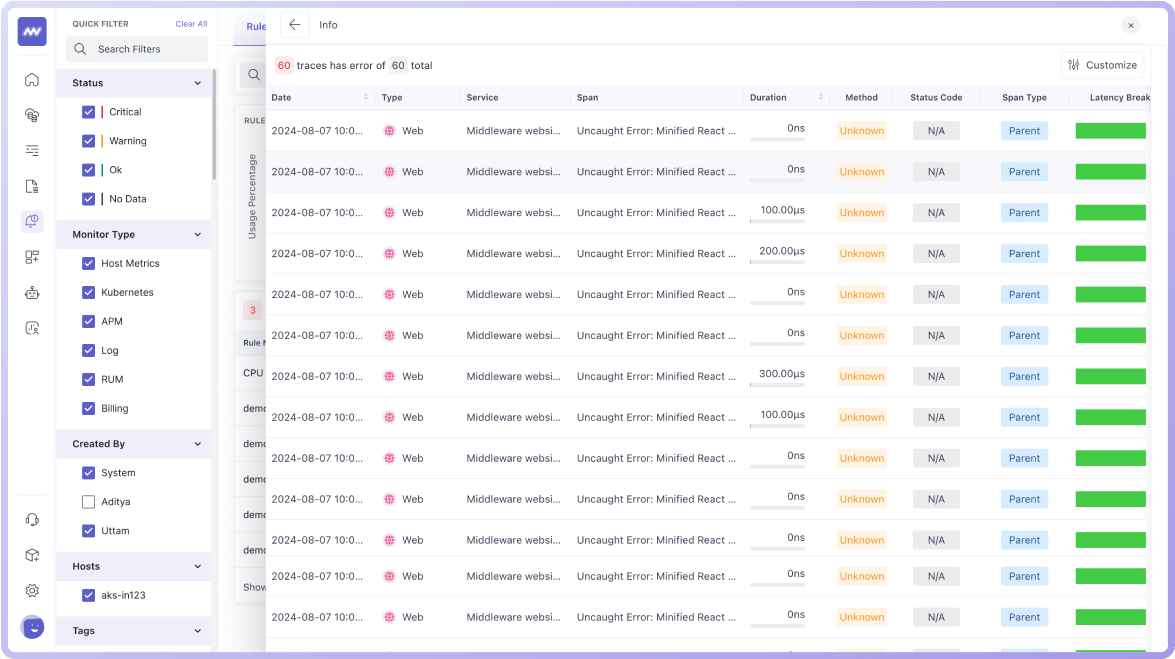
Data-Driven Insights
- Create alerts for logs, APM, Kubernetes, and other metrics.
- Automatic detect anomalies and get alerts for applications, infrastructure, and services.
- Visualize critical SLOs on alert dashboards.