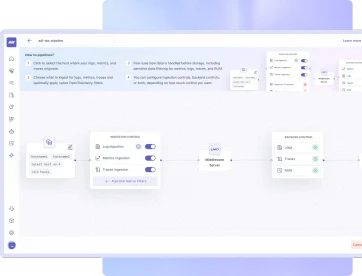
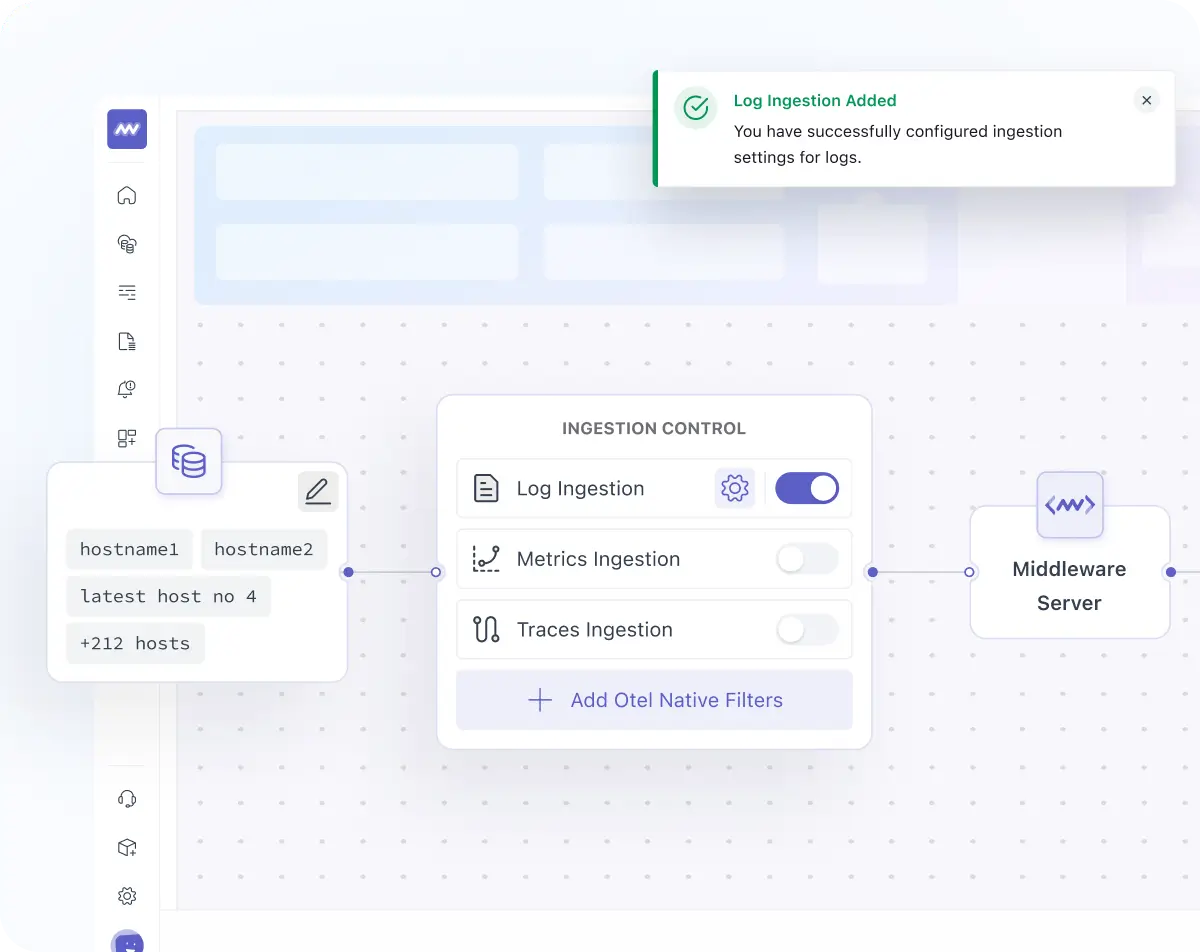
Shape Telemetry as It Enters Middleware
- Control ingestion of data before it enters the platform (for example: enrich it, route it, or sample it).
- Turn logs, metrics, and traces on or off for the selected hosts or clusters.
- Apply different ingestion rules for different sources so each team or environment gets the data you want to monitor.
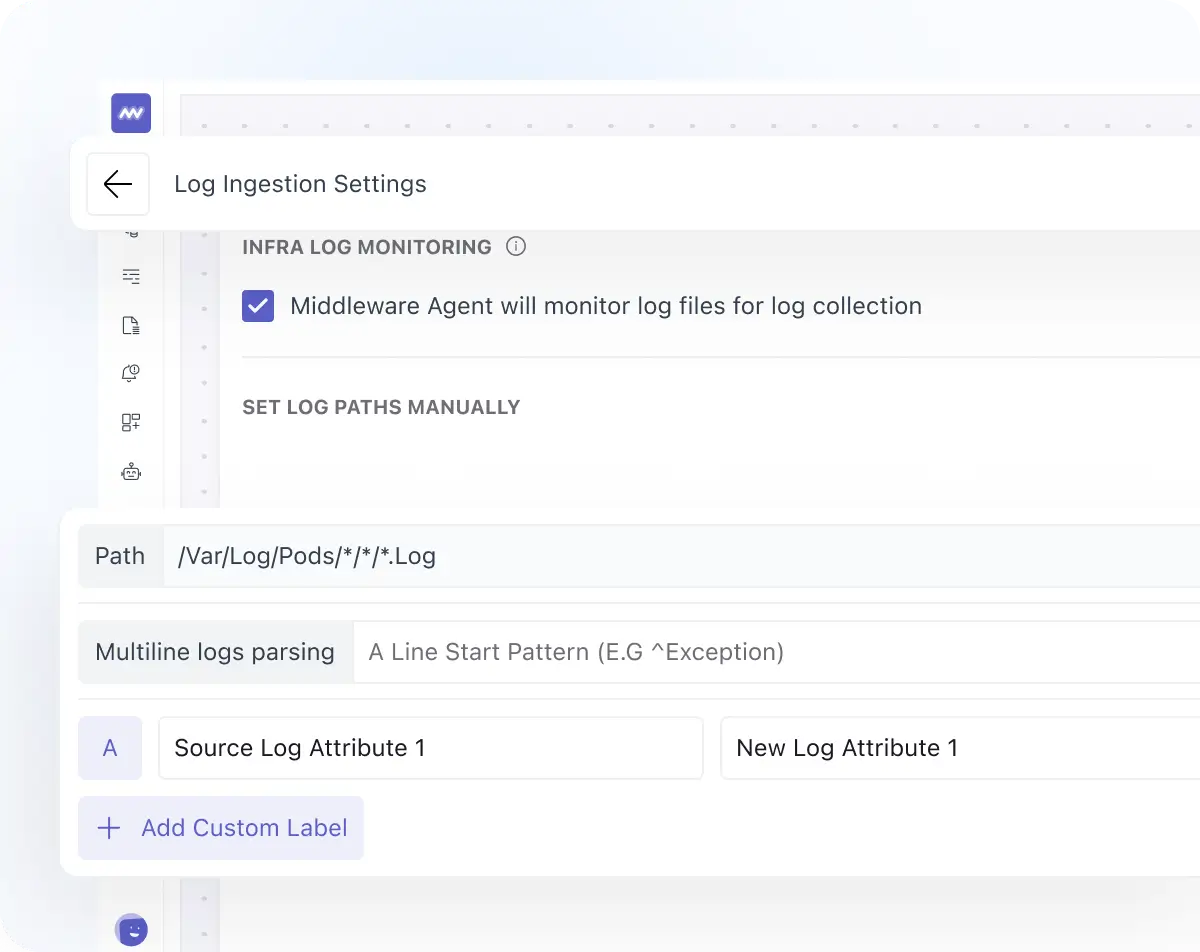
Collect and Parse File Logs at the Source
- Decide whether to collect file-based logs at all using a simple on/off control.
- Pick which files to read using log paths, then add labels so logs are easy to search and filter later.
- Turn raw logs into structured fields using multiline parsing, regex extraction, or JSON parsing.
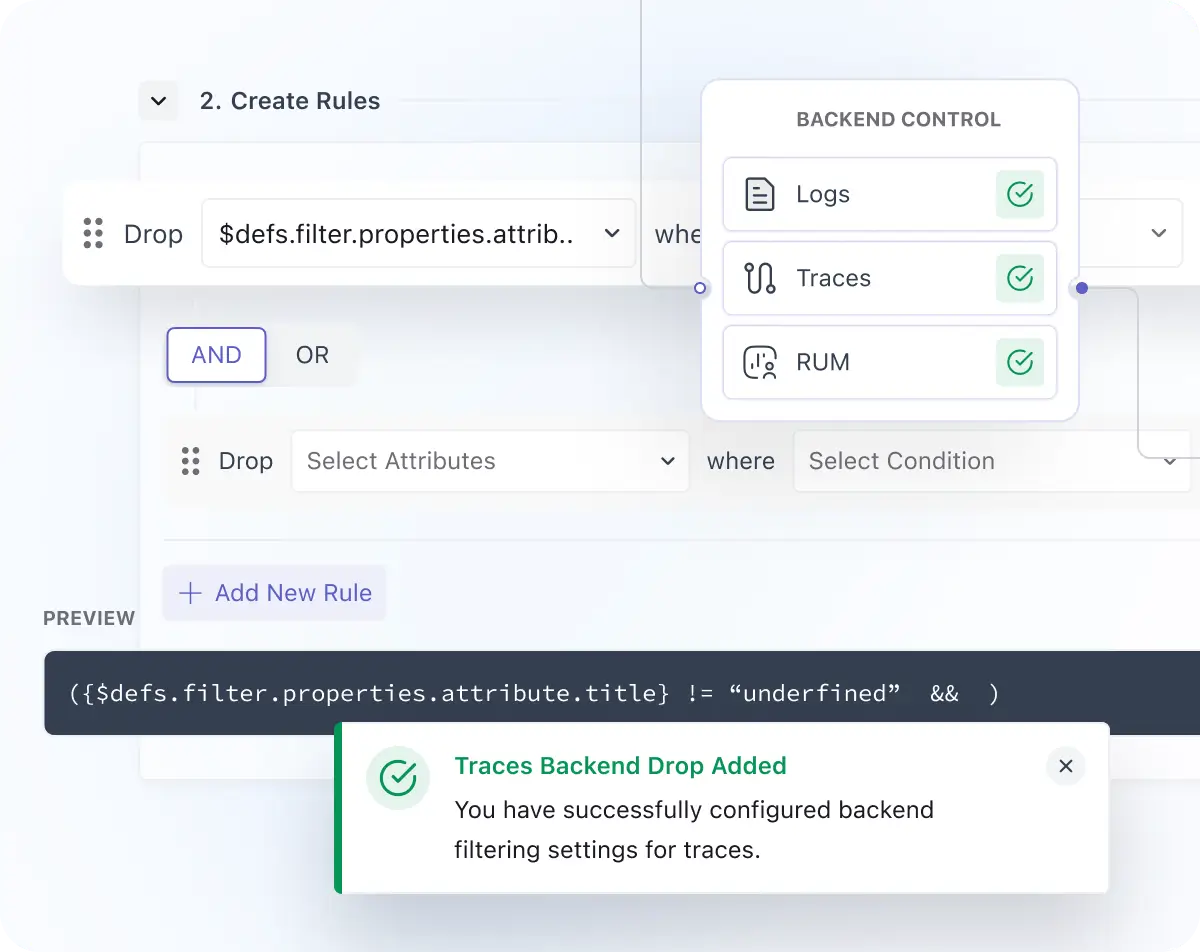
Drop Logs, Traces, and RUM Before Storage
- Set rules to drop data after it is collected but before it is stored, so you reduce noise and control cost.
- Works for Logs, frontend and backend traces, and each signal type can be configured separately.
- If a rule matches, the data is dropped before storage (no storage, no billing, no search).
Filter Telemetry Inside Your Kubernetes Cluster
- Drop noisy logs for Kubernetes Cluster pipeline sources, exclude unwanted metrics, or block traces from specific services before data leaves the cluster using available processors.
- Reduce network usage and infrastructure overhead by sending less data upstream.
