
Artificial Intelligence (AI) is revolutionizing how we process and analyze operational data. In observability, AI-powered insights are proving invaluable not only for infrastructure and applications but also for cloud-native environments and AI/LLM systems.
With the rise of microservices and distributed architectures, traditional monitoring methods are no longer sufficient. AI-based observability platforms, such as Middleware’s OpsAI co-pilot, now deliver real-time analysis, predictive alerts, and even automated remediation, similar to GitHub pull requests.
This marks a shift from reactive monitoring to proactive, intelligent operations. In this article, we’ll explore how AI-powered insights are reshaping observability in 2026 and the benefits they bring to IT teams.
What Are the Limitations of Traditional Observability?
Observability has always been a fundamental aspect of IT operations as a way to understand, observe and monitor systems, applications, and infrastructure. In previous years, observability was achieved by gathering metrics, logs, and traces from servers, networks, and applications, manually reviewing them, and alerting on issues as they arose.
However, traditional observability practices have several limitations given today’s fast and complex IT environments:
Manual Troubleshooting Consumes Time and Resources: IT teams often spend 60–70% of their time troubleshooting issues manually. Each incident required cross-checking logs, metrics, and traces across multiple systems, making the process slow and prone to errors.
Reactive Not Proactive: Traditional observability has a reactive focus on identifying issues from an incident once the failure has occurred, which leads to downtime and slower response times.
Difficulty Managing Large Volumes of Data: Modern applications generate a massive amount of server logs, metrics, and events. Legacy observability tools don’t efficiently process and correlate data, so it’s difficult for a human operator to detect trends or issues.
Limited Context and Root Cause Analysis: Alerts often provide minimal context, forcing teams to investigate the underlying causes of failures manually. Without automated insights, root cause analysis is time-consuming and usually incomplete.
High Operational Costs: When monitoring and remediation are done manually, the human cost is substantial, and operational costs and resource demands can escalate.
As organizations scale and adopt cloud-native architectures, microservices, and AI systems, these limitations make traditional observability insufficient. This is why AI-powered observability has emerged, providing automated insights, predictive analytics, and faster issue resolution to replace manual, resource-intensive practices.
AI-based insights have transformed the infrastructure monitoring landscape by providing an intelligent and automated approach to observability. This approach involves using machine learning algorithms to analyze large volumes of data to identify patterns that may indicate potential issues and AI-powered solutions to fix them.
How Will AI-Powered Insights Transform Observability in 2026?
AI-based insights have revolutionized the world of DevOps in 2026, and it is expected to change it even further in 2026. Integrating AI into Ops has enabled the automation of various processes, streamlining workflows and reducing Mean Time to Repair (MTTR).
With AI-based insights, organizations can leverage smart alerts that can detect and diagnose issues in real-time, along with their possible solution, enabling IT teams to respond quickly and prevent further disruptions.
By using machine learning algorithms and predictive analytics, AI monitoring insights can analyze vast amounts of data and identify potential issues before they occur. This helps IT teams to proactively address these issues, reducing the time required to identify and resolve them.
Furthermore, AI insights can aid in root cause analysis, enabling teams to pinpoint the underlying cause of the issue and prevent it from recurring in the future.
What Are the AI-Powered Observability Capabilities?
Artificial intelligence and automation are changing observability, helping identify, analyze and resolve issues affecting the systems operated by IT teams more quickly than before. By applying approaches such as anomaly detection, predictive analytics, and automated incident response and remediation, AI observability enables teams to reduce reliance on manual troubleshooting, improve the reliability of the systems, and help teams proactively reduce potential downtime.
Here are the key AI-powered observability features that Middleware offers:
1. AI Observability Copilots
AI observability copilots act as intelligent assistants for IT teams. They detect issues, analyze root causes, and provide actionable recommendations or, in some cases, automate remediation.
Middleware OpsAI is an AI observability co-pilot that works across any platform, language, or framework. Ops AI can detect and fix issues across both your frontend and backend. With full awareness of your codebase, it delivers accurate, pinpoint insights into exceptions.
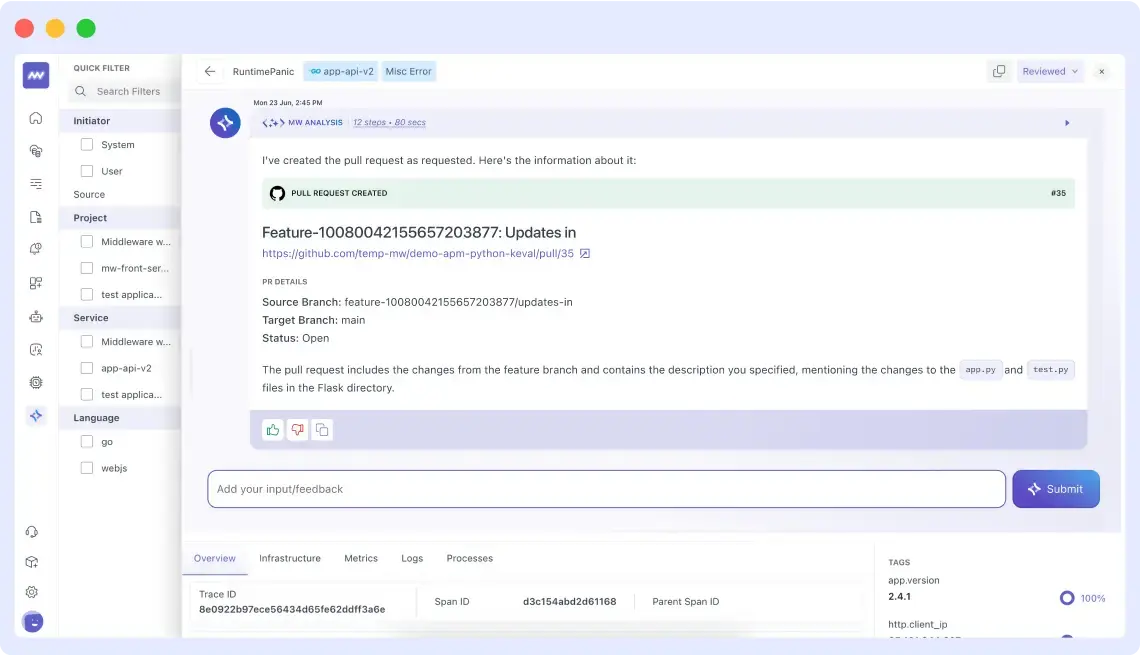
With Middleware, OpsAI automatically detects, diagnoses, and even fixes infrastructure and application issues, giving you full visibility and smarter insights. Activate Free Account.
Refer here to understand how OpsAI works in detail. OpsAI works in three steps: it detects the error, finds a solution, and either applies the fix directly or generates a pull request for developer review.
Key Functions:
- Continuously monitors applications, infrastructure, and cloud-native environments in real time.
- Detects errors, anomalies, and unusual behavior across logs, metrics, and events.
- Performs root cause analysis to identify the source of issues.
- Provides actionable recommendations for issues requiring manual intervention.
- Follows a three-step workflow: detects the error → finds a solution → applies the fix automatically or generates a pull request for developer review.
- Automates remediation for supported infrastructure and application issues, reducing manual troubleshooting time.
- Prioritizes critical issues to help teams focus on high-impact problems first.
2. Automated Anomaly Detection
Anomaly detection identifies unusual patterns or behaviors that deviate from expected system behavior. This helps teams catch issues before they escalate.
Middleware expanded anomaly detection to cover both log streams and alert events, allowing teams to catch unusual behaviors with greater precision. Anomaly detection is the process of identifying abnormal patterns, behaviors, or events that differ from the expected behavior. Such deviations can be an indication of potential fraud, security breaches, system failures, or operational failures, among other problems.
Detect anomalies faster in your Kubernetes apps. see our step-by-step guide on Monitoring Kubernetes Applications with Middleware.
To detect anomalies, organizations train their systems to detect normal behavior and watch for outliers. This may involve reviewing data streams, logs, or transactions to identify defects that would not take place in everyday scenarios.
Middleware offers two types of anomaly detection: one for logs and another for alerts.
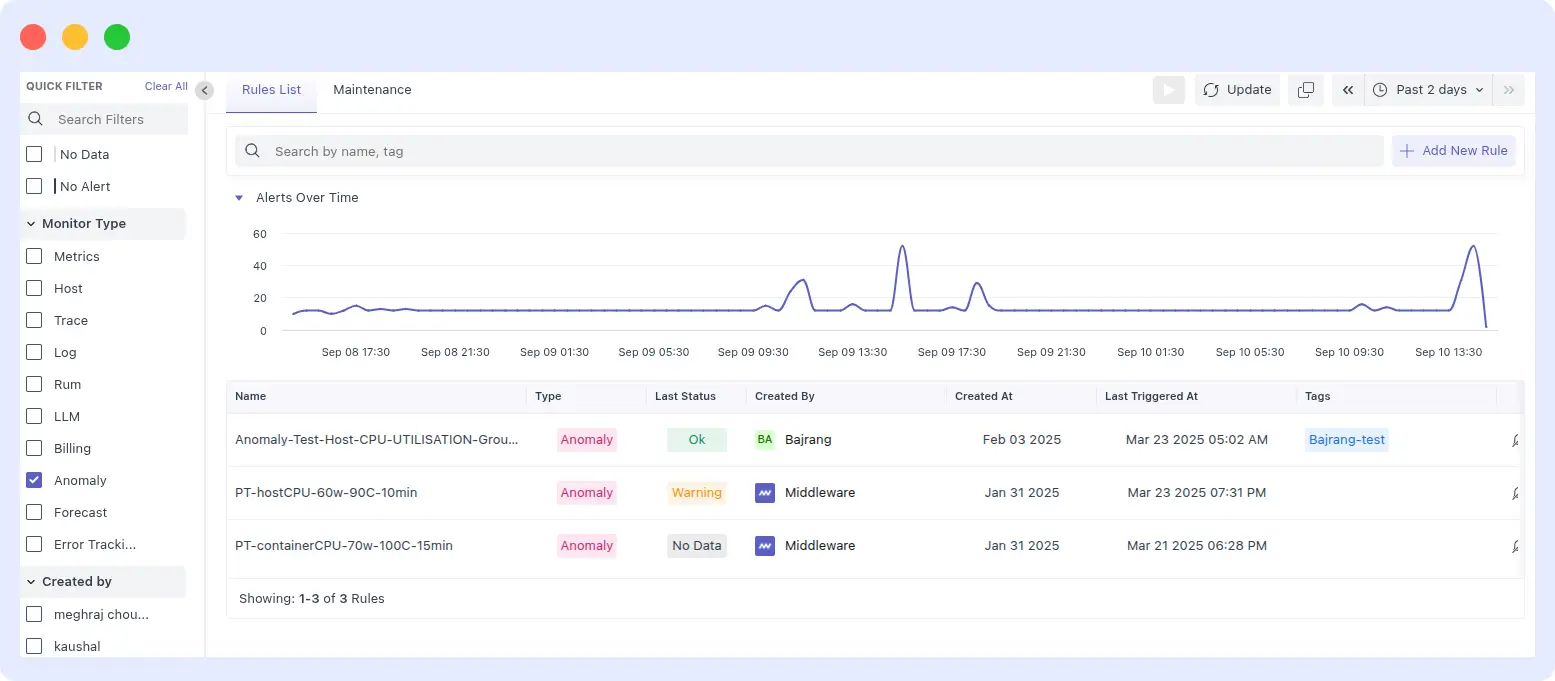
Key Functions:
- Continuously monitors logs, metrics, and alert events for anomalies.
- Identifies deviations from normal behavior in real time.
- Reduces false positives through intelligent filtering.
- Provides actionable insights for proactive resolution.
- Integrates with communication platforms for smart, timely alerts.
3. Kubernetes and Cloud-Native Observability
AI observability is essential for containerized and microservices architectures. It enables teams to monitor clusters, nodes, and pods, providing actionable insights for complex cloud-native environments.
Middleware upgraded K8s Ops AI with cluster overview dashboards, topology visualizations, and deployment timeline views, making troubleshooting cloud-native environments even simpler.
Kubernetes (K8s) Ops AI specializes in Root Cause Analysis (RCA) and automated remediation within Kubernetes environments by detecting anomalies across pods, nodes, and services. It delivers Kubernetes-specific recommendations to resolve performance, resource, and configuration issues, significantly simplifying troubleshooting in cloud-native, containerized setups.
To get started, teams can quickly deploy the K8s Install Agent, which seamlessly connects their clusters to Middleware. Once installed, the agent collects metrics, logs, and events in real time, enabling OpsAI to provide actionable insights, anomaly detection, and automated fixes without manual intervention.
Encountering pod failures? Learn how to resolve them with our Exit Code 137 Causes, Diagnosis & Fixes tutorial.
Key Functions:
- Specialized root cause analysis and automated remediation focused on Kubernetes environments.
- Provides Kubernetes-specific recommendations to fix performance, resource, or configuration issues.
- Simplifies troubleshooting in cloud-native, containerized environments.
4. AI/LLM Observability
For teams that are deploying AI models or large language models (LLMs) observability will give them confidence that their model is reliable, efficient, and transparent.
Observability goes beyond latency metrics, token consumption, and monitoring unexpected behavior from models, to enable modern AI observability on granular tracing and monitoring, tracking multi-turn interactions with LLMs, tracing agent workflows, and tracking external tool integration, all in real time. This surpasses traditional application traces and allows teams to understand complex interactions within their AI systems.
In addition, AI observability tools support automated detection and evaluation. They can detect data drift, concept drift, or bias emergence in real time and perform continuous model performance evaluation using metrics such as accuracy, precision, recall, response time, and fairness. This frees teams from manual triage and ensures that AI systems maintain reliability and fairness throughout their lifecycle.
For example, tracing allows you to see how a model processes a prompt and how much time it takes to respond, revealing latency issues or inefficiencies that traditional monitoring might miss.
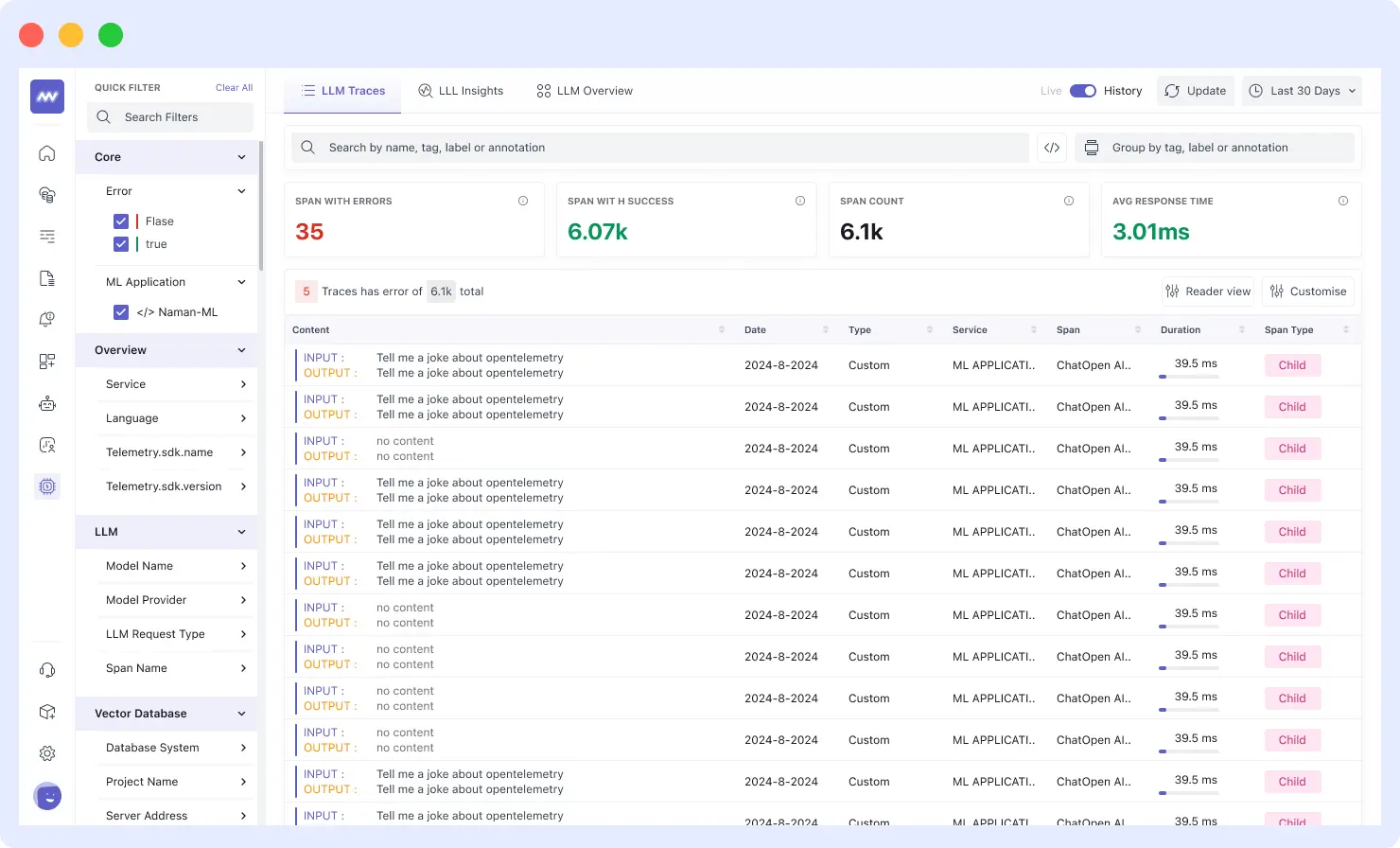
Key Functions:
- Traces multi-turn LLM interactions, agent workflows, and external tool calls.
- Monitors latency, token usage, throughput, and errors for AI models.
- Detects model anomalies, performance degradation, and bias emergence.
- Evaluates model performance continuously in both real-time and batch modes.
4. Predictive Analytics to Forecast Failures
Forecasting or predictive insights involve analyzing historical data and trends to estimate future outcomes, enabling businesses to make informed decisions and plan effectively. These insights help optimize resource allocation, manage risks, and seize growth opportunities by anticipating market changes and customer needs.
Accurate predictions require precise metrics; discover how to monitor Kubernetes Metrics effectively with Middleware.
Key Function:
- Forecasts future system failures or performance degradations.
- Provides preventive recommendations to avoid downtime.
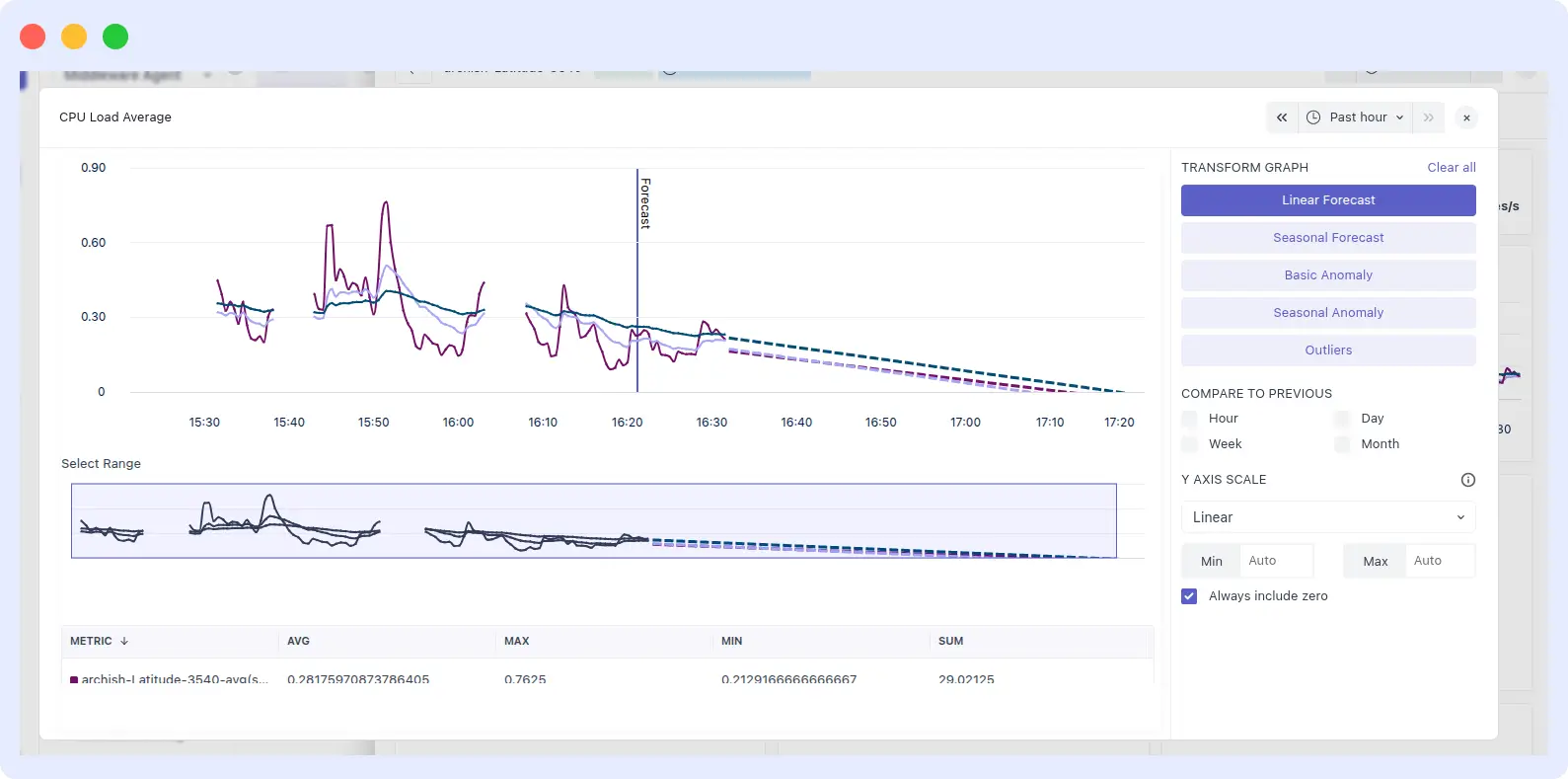
Forecasting is of 2 types: linear and seasonal.
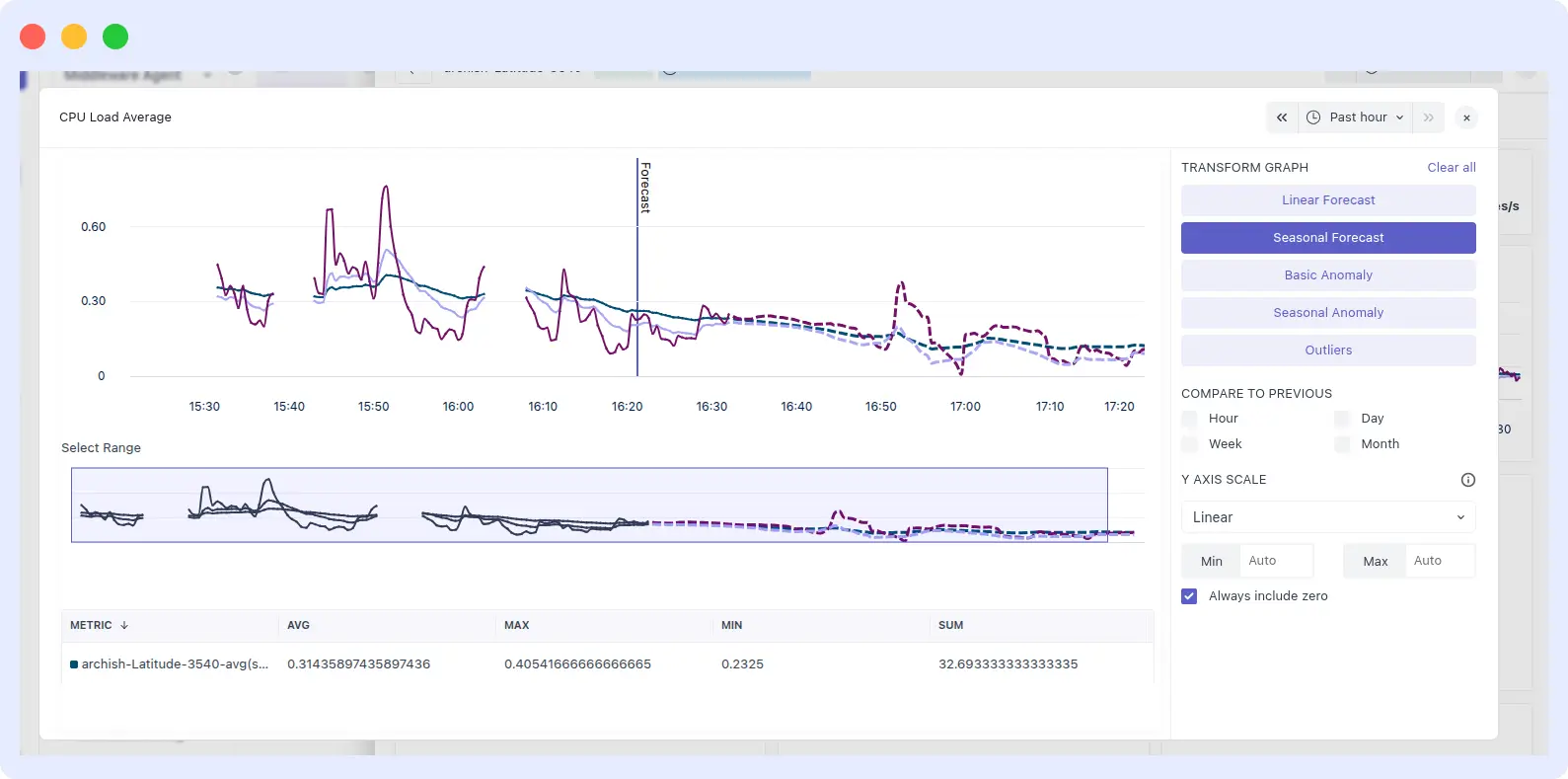
Middleware’s forecasting now includes both linear and seasonal predictions, helping teams pre-empt cloud cost spikes and workload bottlenecks.
5. Transparency, Security, and Compliance
Modern AI observability emphasizes explainability and compliance. Observability tools provide deep insights into how AI models make decisions, exposing contributing factors behind outcomes. They also support alignment with regulatory frameworks, such as the European AI Act, ensuring ongoing monitoring, transparency, and human oversight.
Key Functions:
- Provides explainable AI outputs, highlighting factors behind decisions.
- Supports compliance with AI governance and regulatory frameworks.
- Enhances trust and accountability in AI systems.
6. AI-Driven Correlation Engines
Using AI-based correlation engines, it can analyze and link data from various sources, including logs, metrics, traces, and events, to identify patterns and relationships that may suggest potential issues.
These engines are particularly useful in complex, distributed and cloud-native ecosystems, and failures can impact many services, nodes, or containers. AI-enabled engines help eliminate noise by automatically correlating anomalies and prioritizing incidents, allowing AI copilots like OpsAI to recommend the right steps for remediation accurately.
Key Functions:
- Correlates data from logs, metrics, traces, and events for comprehensive insights.
- Detects relationships between seemingly unrelated anomalies or failures.
- Prioritizes incidents by severity and potential business impact.
- Reduces alert fatigue by filtering duplicates or low-priority alerts.
- Supports faster root cause analysis for infrastructure, applications, and AI systems.
- Provides actionable context for AI copilots to suggest automated or manual fixes.
Benefits of AI Observability for Modern IT Teams
With Middleware’s AI-based insights, you don’t need to inspect each service and machine to identify issues. MW AI advisor lists all the problems with details like affected resources and detailed solutions so that you can make the fix faster. To help teams experience AI-powered remediation, Middleware offers a “Fix First 10 Errors Free” program where OpsAI automatically resolves the first batch of critical errors at no cost.
Additionally, AI-based insights will help you identify and resolve infrastructure issues before they impact your users.
Conclusion
With AI-powered insights, observability now extends across infrastructure, applications, and large language models. Middleware gives IT teams not just monitoring, but intelligent auto-remediation, predictive forecasting, and cost-aware observability controls. With OpsAI and other upgrades in 2026, Middleware is reshaping how teams detect, diagnose, and resolve issues.
Middleware is offering AI-powered insights for free to all its users. So grab the opportunity to give it a try. Sign up now; it’s free.



