
Programming paradigms like stream processing are needed with the rise of big data and analytical technologies. DevOps analysts can analyze a simple data packet without any interdependence. The problem arises when dealing with data streams.
For the same reason, they depend on stream processing, which can apply queries on data streams. Before the adaptation of stream processing, people referred to it as real-time processing. As of now, it is a specific manner for taking action on a series of data. Read on to know more about stream processing and its importance.
What is stream processing?
Simply put, stream processing is the practice of taking action on a series of data at the time of data creation. Some people may refer to it as real-time processing. Both indicate the same thing, which is analyzing the data when and whenever it is required.
Stream processing helps data experts to take action on a series of incoming data. Tasks on the incoming data streams are performed serially or parallelly, depending upon the requirement.
Data experts complete the entire process in a stream processing pipeline. It is the workflow through which the stream data is generated, processed, and delivered to the required location. There are numerous actions related to data streams. These actions include aggregation, ingestion, enrichment, analytics, transformation, and other data-related activities.
With the help of stream processing, one can respond to the new data at the moment it’s generated. Therefore, it is one of the most critical programming paradigms in different languages and technologies. Stream processing applications are often developed with big data, Spark, Java, Azure, IoT, and other technologies.
How does stream processing work?
One should know that stream processing is applied when data is available as a series of events. For example, it can help analyze the data produced from a payment gateway page because gateway pages produce streams of data in a series of events. Similarly, stream processing is applied to data produced from server logs and application logs.
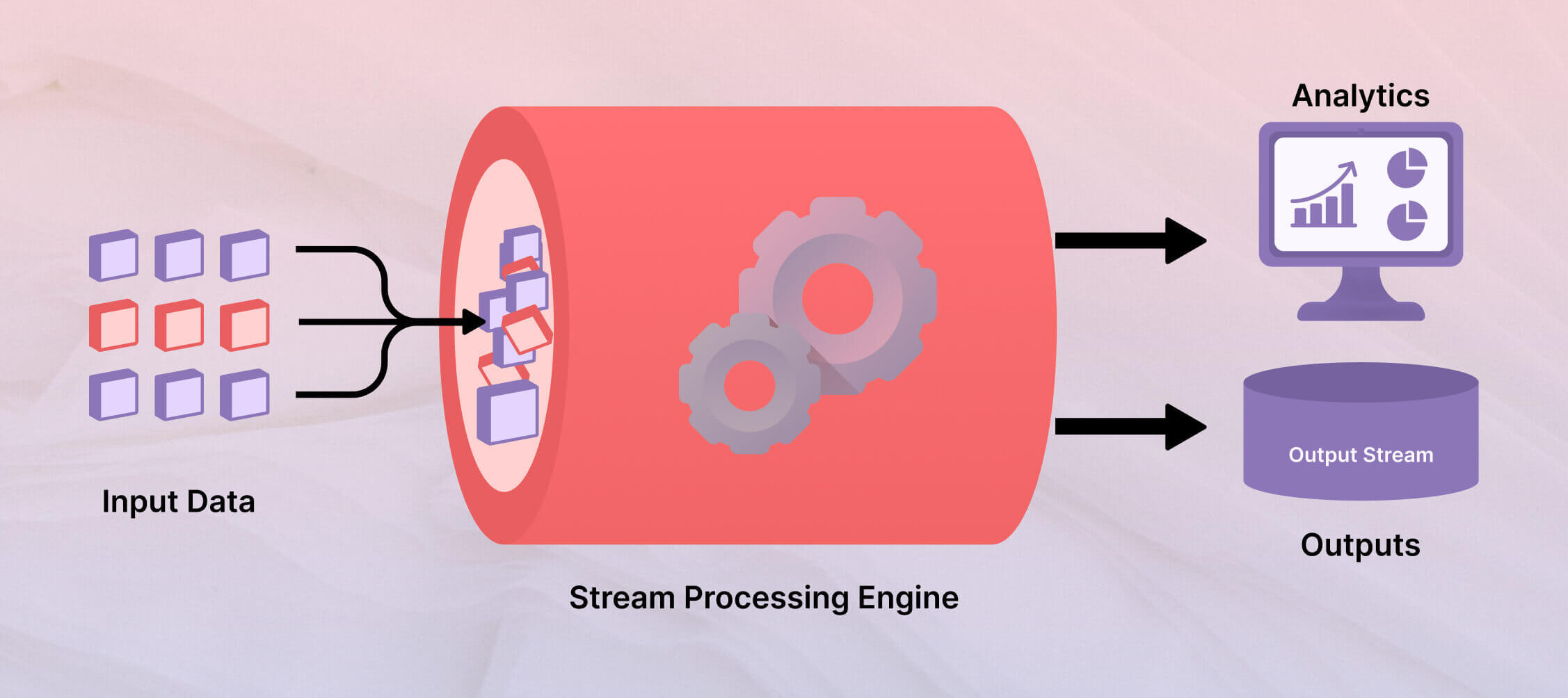
After a publisher/source generates the data, it is transferred to a stream processing application. The application/algorithm will test, enrich, and transform the data streams.
Once the desired action has been taken on the data stream, it is moved to the final location. In the context of a stream processing application, the data is always transferred to the sink or subscriber. From a technical point of view, the sinks and sources for stream processing include big data repositories or data grids.
For example, stream processing Kafka in Java helps analyze data streams as they occur.
Why is stream processing needed?
Every data point holds a value or an insight. However, the case might not be the same with data streams. Some insights (after data processing) are valuable only at the exact moment. After a period, the data insight might not be as useful as before.
Therefore, there is an eminent need to process insights faster in most cases, even within milliseconds. Stream processing makes it possible to generate insights in real-time.
Some more reasons to use stream data processing are as follows:
- Sometimes, we encounter never-ending streams of data. We have to detect the insights and generate results in a never-ending circle. Where other programming paradigms fail, stream processing can easily handle never-ending streams of data and perform actions.
- Sometimes, we need to spread the data processing over a period. Unfortunately, other programming paradigms, like batch processing, fail to achieve this objective.
- There are instances when approximate answers are ample. Stream processing applications use systematic load shedding to produce approximate solutions with ease.
- Sometimes, we cannot store vast amounts of data packets. In such a case, data stream processing helps handle large volumes of data and retain only valuable bits.
- The demand for stream processing applications will also increase with the rise of streaming data. In addition, with the growth of IoT devices, websites, payment portals, and digital transactions, there is a need to handle streaming data. To put things into perspective, here’s a quick fact. An average person produces over two quintillion bytes of streaming data.
Use Cases: Examples
Some use cases of stream processing around us are as follows:
- Infrastructure monitoring:
Stream processing algorithm is used in Infrastructure monitoring, where one agent continuously processes the data generated from server logs and application logs for any errors or faults. The same agent then sends that data to the analytics system to display it visually.
- Fraud prevention
Stream processing is widely used around the globe for detecting fraud and anomalies in real-time. For example, stream processing algorithms can monitor credit card transactions continuously. They can block or generate an alert for an unauthorized or fraudulent transaction.
- Personalized Ads
Marketers rely on stream processing algorithms to offer customers personalized ads and marketing content.
- Data analysis
Manufacturing, refinery, and logistics companies have to deal with huge volumes of data. Many companies rely on IoT devices to collect information regarding operations. With stream processing, companies are making sense of the large volumes of data.
Stream processing vs. Batch processing: What’s the difference
Batch processing takes action on the available data according to a schedule. For example, there can be a rule that the data will be processed daily at 1 PM. The threshold could also be that the data will be processed when it reaches 100 GB. However, the pace and volume of data have augmented, and batch processing fails.
Contrary to batch processing, stream processing makes sense of data streams in real time. Therefore, we can respond to new data events when they occur with stream processing.
History of the origin of stream processing
When active databases were developed, stream processing started to gain hype. Active databases allowed users to run queries on the stored data. As a result, many stream processing frameworks have been developed over the years. TelegraphCQ is among the first stream processing frameworks. In the last few years, stream processing and complex event processing have been merged in most of the frameworks.
Conclusion
Data scientists and experts should know what stream processing is. It is already being used for personalized marketing, IoT edge analytics, real-time fraud detection, and other purposes. Start analyzing streams of data in real-time with stream processing.
Now that you know what stream processing is and how it works. Signup on our platform to experience how we use it to provide container monitoring, log monitoring, Infrastructure monitoring and more.
FAQs
What do you mean by stream processing?
It is a programming paradigm to derive insights from data streams in real-time.
Why is stream processing important?
Programming paradigms like batch processing cannot perform real-time analytics. Stream processing frameworks address this drawback.
What are stream processing engines?
A stream processing engine will perform analysis when the data is in motion. On the other hand, a map-reduce engine performs analysis when the data stream is at rest.
What is Kafka stream processing?
Kafka is a stream processing library available for Java users. It can help develop programs to analyze data streams in real-time.
What is event stream processing?
It is a type of reactive programming that analyses and filters the data as it arrives from the streaming source.



