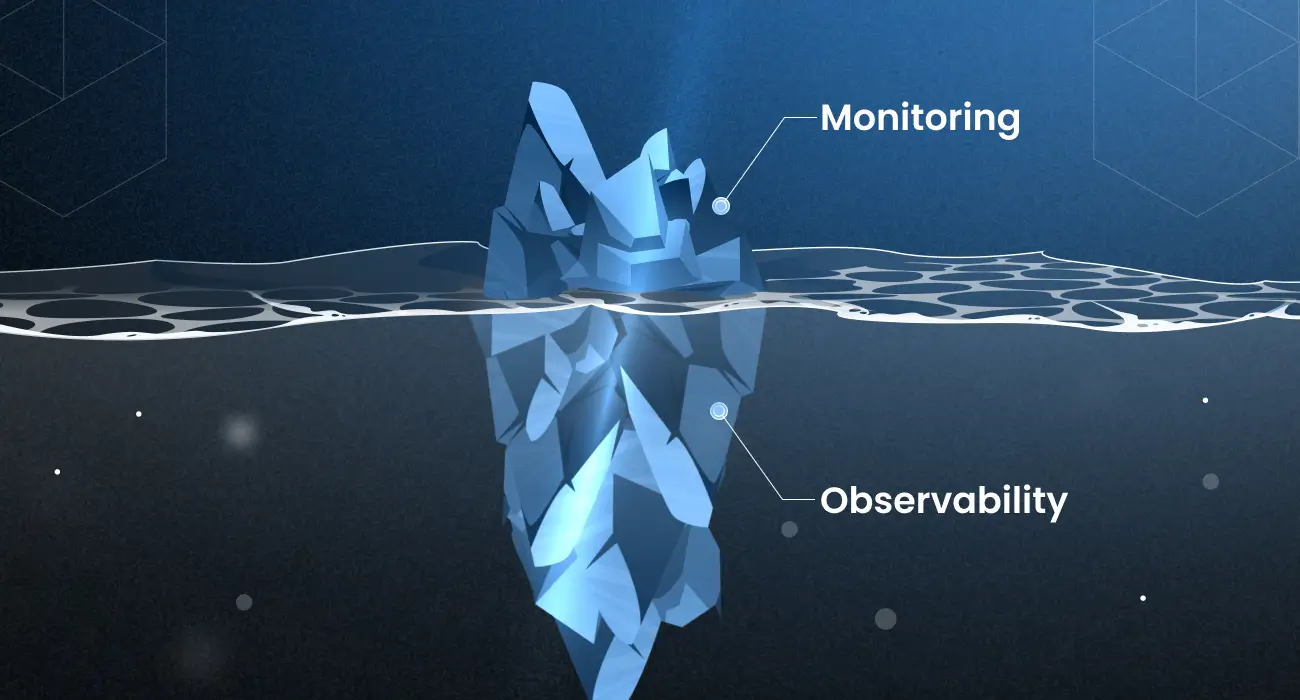
Monitoring alerts you when something breaks. Observability tells you why it failed. Monitoring utilizes predefined metrics, while observability analyzes logs, metrics, and traces together to provide a comprehensive system context.
Imagine your app crashes during a product launch. Monitoring tells you the CPU spiked. Observability tells you why. That’s the difference.
Monitoring alerts you when something goes wrong, while observability helps you understand why. In this guide, we’ll explore their key differences and how they work together.
What is Observability?
Observability is the ability to understand what’s happening inside a system by analyzing the data it produces, primarily logs, metrics, and traces. It helps DevOps and IT teams gain deep insights into the health, performance, and behavior of applications and infrastructure.
Get full-stack observability, faster root-cause detection, and lower MTTR with Middleware’s cloud-native platform.
By utilizing observability tools, teams can identify issues, pinpoint root causes, and resolve problems more efficiently, particularly in complex, cloud-native environments. Observability extends beyond monitoring by providing the full context necessary to understand not only that something is wrong, but also why it’s happening.
What is Monitoring?
Monitoring is the process of continuously collecting and analyzing data from a system to track its performance, health, and availability. It helps teams detect problems early by using predefined metrics and alerts. Monitoring tools notify you when something goes wrong, such as a server going down or response time spiking, so that you can take action promptly. It is essential for maintaining system stability and is often the first step in identifying operational issues.
Observability vs Monitoring: What’s the Actual Difference?
Keeping track of systems is essential for DevOps teams to understand the state of their applications. This involves collecting and displaying data from multiple IT sources, which enables them to identify when something is amiss. But it’s hard to get to the bottom of it without the aid of observability.
Observability and monitoring together give a complete view of the IT infrastructure. Monitoring serves as an early warning system, and observability helps pinpoint the origin of the problem and determine the best course of action to resolve it. Monitoring an endpoint’s performance is essential even when it cannot be observed directly, since it provides additional data that can be used to identify and address any issues with the system.
Here’s a detailed comparison of observability vs monitoring to understand their unique roles and how they complement each other.

For development teams, the distinction between observability and monitoring is often blurred. Let’s discuss observability versus monitoring and their interrelationship.
Collection vs. Context
Monitoring notifies you if a fault occurs in the system, using a predetermined set of metrics and logs. You can identify a predetermined set of failure modes by monitoring applications.
Monitoring technologies like application performance monitoring (APM) can inform you whether a system is online or offline, or whether there is an issue with the performance of an application.
Observability tells you what the problem with a system is and how it was caused. It combines the information and data generated by monitoring to provide a comprehensive understanding of your system, including its performance and health.
An eCommerce site observed a sudden spike in 500 errors. While monitoring alerted the spike, observability helped trace it to a failed downstream API due to missing auth headers.
Tracking vs. Knowledge
Monitoring is the process of tracking a system’s performance over time. Metrics are used by monitoring systems to notify IT teams of operational issues with applications and cloud services. The main use of monitoring is to alert teams if there are any issues with the system.
The degree to which the system’s internal states may be deduced from knowledge of its external outputs is measured by its observability. It combines the information and data that monitoring generates to give you a comprehensive understanding of your system, including its performance and health.
Therefore, the degree to which your monitoring measures can decipher your system’s performance indicators will influence its observability.
Observability acts as a knowledge base in defining what to monitor, and Monitoring focuses on monitoring the systems and discovering faults.
Data Collection vs. Data Interpretation
In order to gain complete visibility, a complex environment must allow you to interpret its interior state from the data you gather about its surface. This involves, for instance, figuring out that a downed server or memory exhaustion is to blame for your application’s poor response time.
Observability is driven by surface-level data, which can take many different shapes. They include data from complementary systems, such as CI/CD pipelines or help desks, which provide crucial context for data, as well as logs, traces, and metrics from the software and infrastructure used in the environment where applications are run.
Monitoring provides data on a program’s usage trends and performance. One objective of monitoring is to achieve high availability by reducing important time-based KPIs. Application and service monitoring depend on features like real-time streaming, historical replay, and visualizations.
A well-monitored, Observability driven deployment provides data about its performance and health, enabling the team to identify production incidents quickly.
Observability focuses on giving context to the data, and Monitoring focuses on collecting data.
Key Criteria vs. Complete Assessment
With Observability, cross-functional teams can better comprehend and respond to precise queries about what’s happening in highly distributed systems. You can identify what is slow or broken and what needs to be done to improve performance. Teams can receive alerts about issues and proactively fix them before they impact users when they have an observability solution in place.
Unlike Observability, in a Monitoring scenario, you keep track of important KPIs that are intended to warn you of performance concerns you anticipate seeing later. Monitoring keeps track of all the KPIs, and you can see if there is any difference between real-time data and a predetermined value.
Observability gives a more complete assessment of the overall environment, while Monitoring focuses on KPIs.
Limited vs. Sustainable
Observability can be used to produce a better product as a sustainable alternative to monitoring operational insights, improved incident management, and quality control. It aids in securing practical insights for quicker feedback loops and better decision-making.
In the context of observability v/s monitoring, Monitoring is limited, while Observability is sustainable.
Single Plane vs. Traversable Map
In monitoring, you focus on setting up key rules and KPIs that need to be tracked. This makes monitoring a single plane as it can only alert you if there is an issue; you cannot map out the origin of the problem. The key assumption in setting up monitoring is that you’re able to predict what kinds of issues you’ll encounter before they occur.
On the other hand, Observability shows you the problem and lets you understand why there is an error or issue. It enables you to explore various scenarios and identify the root of the problem, making it easier for teams to understand and troubleshoot.
Monitoring methods are single plane, while observability is a Traversable map.
Monitoring as a Tool vs. Observability as a Practice
While the term “monitoring” is occasionally used to refer to anything distinct from observability, monitoring is a process that, combined with tracing and logging, makes a system observable as the “three pillars of observability,” monitoring, tracing, and logging, are frequently referred to.
Understanding when anything goes wrong within the application delivery chain is crucial so you can find the underlying problem and fix it before it affects your business.
Monitoring and observability provide a two-pronged strategy. Monitoring provides situational awareness, and observability aids in determining what is happening and what should be done about it.
Observability creates the potential to monitor different events. Monitoring is the process of using observability.
When to Use Observability or Monitoring
Use Monitoring When:
- You want to get alerts when something breaks.
- You need to track system health or resource usage.
- You’re watching specific known metrics or thresholds.
- Your system is simple or monolithic.
Use Observability When:
- You need to find the cause of an unknown or complex issue.
- You’re working with microservices or cloud-native environments.
- You want to trace how data flows across services.
- You want detailed insights to fix problems faster.
In short, monitoring tells you what’s wrong, while observability helps you understand why it’s happening. DevOps teams should use both together for better reliability and faster issue resolution.
What are the Similarities Between Observability and Monitoring?
DevOps teams appear to concur that monitoring and observability are separate operational kinds that solve different issues. Observability and monitoring go hand in hand. Monitoring tools can alert you when something goes wrong, and observability tools can support your investigation if you notice a problem.
| Aspect | Monitoring | Observability | How They’re Similar |
| Purpose | Detect when something goes wrong | Help understand why it went wrong | Both aim to ensure system reliability |
| Data Used | Metrics, logs, alerts | Metrics, logs, traces | Both rely on system-generated telemetry |
| Use Case | Early detection of anomalies | In-depth root cause analysis | Together, they improve incident response |
| Response Time | Alerts immediately | Provides context to resolve issues faster | Help reduce Mean Time to Resolution (MTTR) |
| Automation | Can trigger alerts and actions | Can offer insights and suggestions automatically | Both can integrate into CI/CD and DevOps workflows |
| Role in DevOps | Part of operational monitoring | Part of proactive diagnostics | Both are essential for modern IT and DevOps teams |
| Best Used For | Simple or expected issues (e.g., planned shutdowns) | Complex, unexpected failures (e.g., system crashes) | Used together to handle a full range of incidents |
Because not all issues found by monitoring technologies call for in-depth analysis, pairing monitoring and observability is advantageous.
For example, your monitoring software may warn you that a server has gone offline despite being part of a planned shutdown. In that situation, you don’t need to gather and analyze various data to comprehend what transpired. Simply log the alert and carry on.
However, observability data is essential for quickly troubleshooting major issues. Although you could theoretically gather the same data that observability solutions automatically offer manually, doing so would add time to the incident response process.
Observability tools always guarantee the availability of the data you need to understand a difficult situation. Many systems also provide suggestions or automated analyses that can speed up the process by which teams sort through extensive observability data and locate core causes of issues.
FAQs about Observability vs. Monitoring
What is the main difference between observability and monitoring?
Monitoring tells you when something is wrong. Observability helps you understand why it’s wrong by analyzing metrics, logs, and traces together.
Can you have observability without monitoring?
Yes, you can have observability without monitoring, as observability focuses on understanding system behavior through logs, metrics, and traces. However, without monitoring, you lose proactive alerting and real-time issue detection, making observability harder to act on quickly.
Is Observability part of DevOps?
Yes, Observability is a key part of DevOps. Observability in DevOps refers to the software tools and processes that assist Dev and Ops teams in logging, collecting, correlating, and analyzing vast amounts of performance data from a distributed application to gain real-time insights.
Is monitoring a subset of observability?
SRE teams use monitoring to check the overall health of individual servers, networks, and data storage in today’s DevOps environment. Monitoring is a subset of an environment’s overall observability goals.
What does observability mean in IT?
Observability is the ability to measure a system’s current state based on data it generates, such as logs, metrics, and traces, in IT and cloud computing. Observability is based on telemetry derived from instrumentation from your multi-cloud computing environments’ endpoints and services.
What is monitoring in DevOps?
DevOps monitoring entails overseeing the entire development process, beginning with planning and ending with deployment and operations. It involves obtaining a comprehensive and real-time picture of the status of applications, services, and infrastructure in the production environment.



