
In July 2024, a major CrowdStrike outage led to widespread disruptions across essential sectors, from healthcare to aviation, due to a flawed update that triggered system crashes on millions of devices. This incident revealed that traditional deployment processes and delayed alerting systems can fall short when rapid, large-scale issues arise.
Had real-time alerting been in place to flag anomalies as they started, companies might have contained the issue before it escalated. Instead, organizations scrambled to mitigate the fallout, showing the costly risks of delayed detection.
This article delves into the significance of near real-time alerting for critical services. We’ll examine how real-time detection can protect systems, contrast common polling intervals in the industry, and discuss why Middleware’s approach to alerting offers a faster, more proactive solution than delayed windows.
By the end, you’ll understand how real-time alerting can keep services up and running, mitigate risks, and ensure smooth, uninterrupted operations in high-stakes environments.
Understanding the importance of real-time alerting
When major issues arise—like a CPU spike or a sudden service outage—the speed of alerting is crucial in determining how fast your team can respond.
Real-time alerting empowers teams to respond the moment a problem is detected, preventing minor issues from snowballing into significant disruptions.
However, alert speed is often limited by a tool’s data polling interval, the frequency with which it checks and collects data. Many observability tools operate on delayed polling windows, meaning that issues may go undetected for several minutes before an alert is triggered. This delay can translate to downtime, user dissatisfaction, and revenue losses.
Unlike delayed alerting systems, which depend on longer polling intervals, real-time alerting systems monitor data continuously and notify teams as soon as an anomaly is discovered. For services requiring high uptime and reliability, real-time alerting minimizes risks by shortening the window between detection and response.
Common monitoring and polling intervals in the industry
The speed at which monitoring tools detect issues depends heavily on their polling intervals. Here’s a breakdown of the polling intervals for some leading observability tools:
Datadog: Default polling every 5 minutes
Datadog has a default 5-minute polling interval for many cloud infrastructure services. While this interval works for general performance monitoring, it can be too slow for high-priority environments. Several users on platforms like Reddit have raised concerns about Datadog’s slow alerting system, pointing out that critical issues could go unnoticed for extended periods.
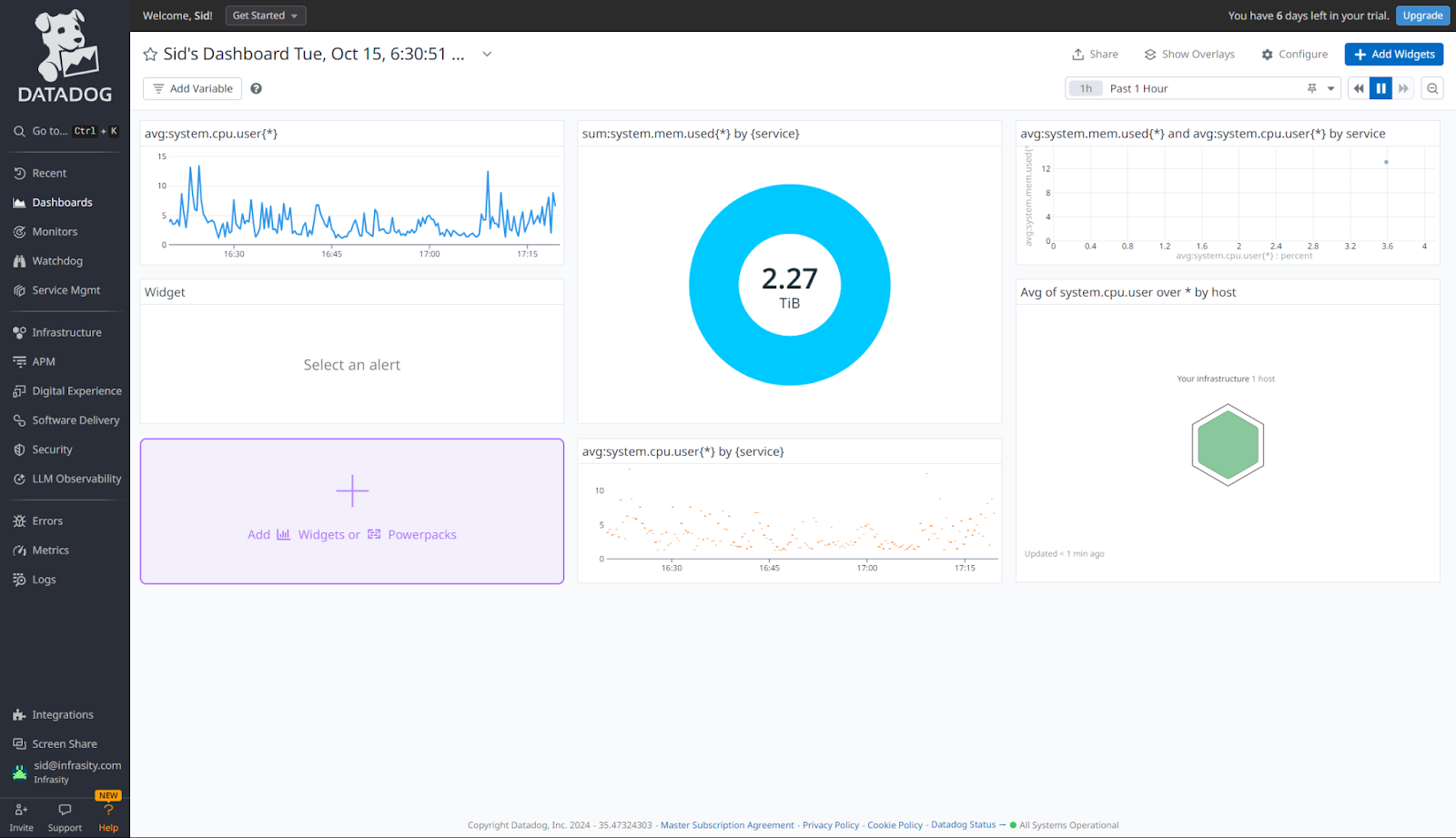
Editor’s Pick: Datadog Pricing: Is it Worth Spending for in 2024?
New Relic: Default polling of 1 minute
On the other hand, New Relic uses a 1-minute polling interval for most of its integrations. This is faster than Datadog, but even a one-minute delay could allow a critical issue to go undetected for too long in some environments.
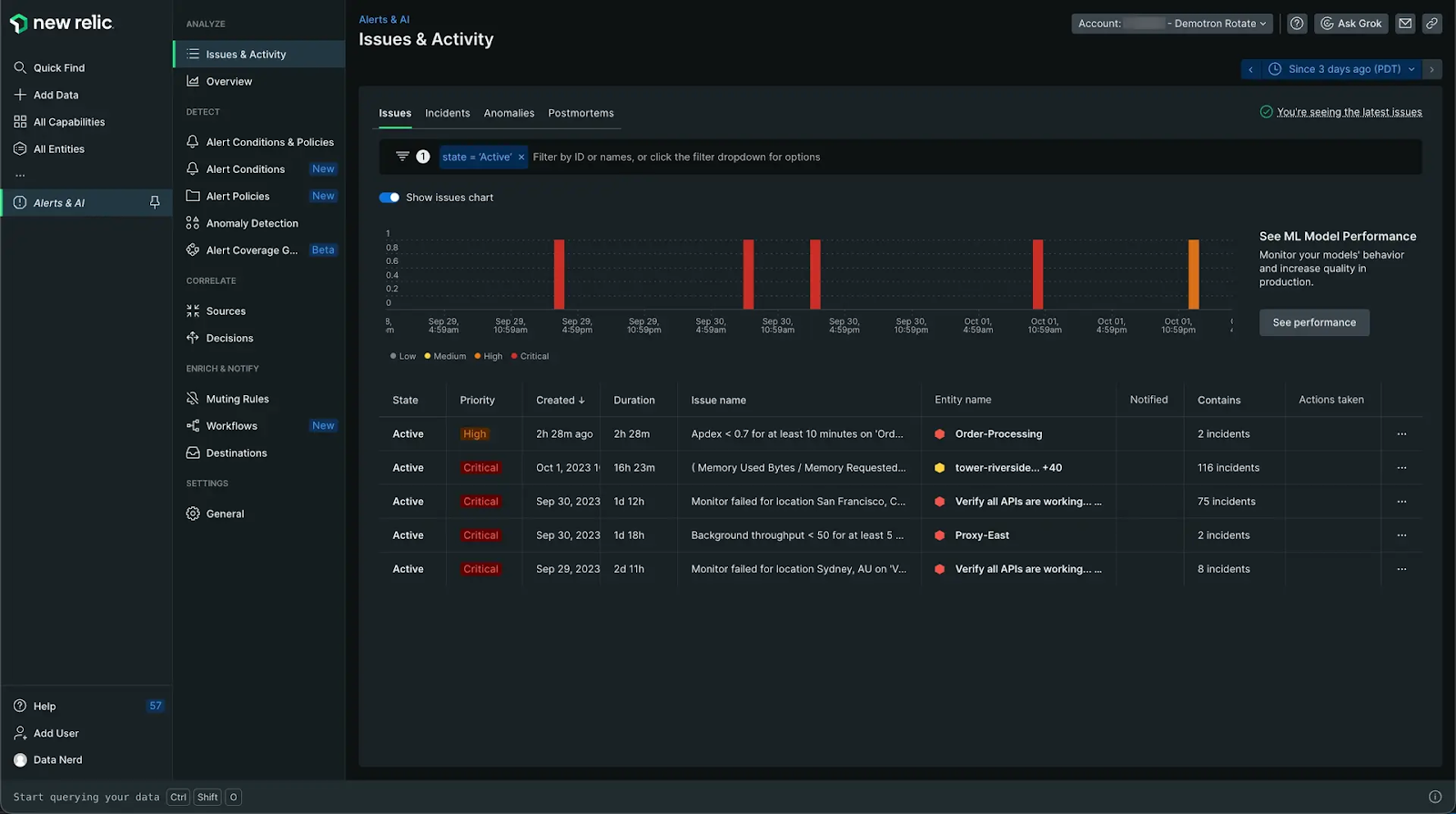
Editor’s Pick: New Relic Pricing: Still Worth it in 2024?
Dynatrace: Default polling of 1 minute
Dynatrace also operates with a 1-minute default polling interval. While sufficient for many use cases, like New Relic, it may not be fast enough for mission-critical systems that require immediate awareness.
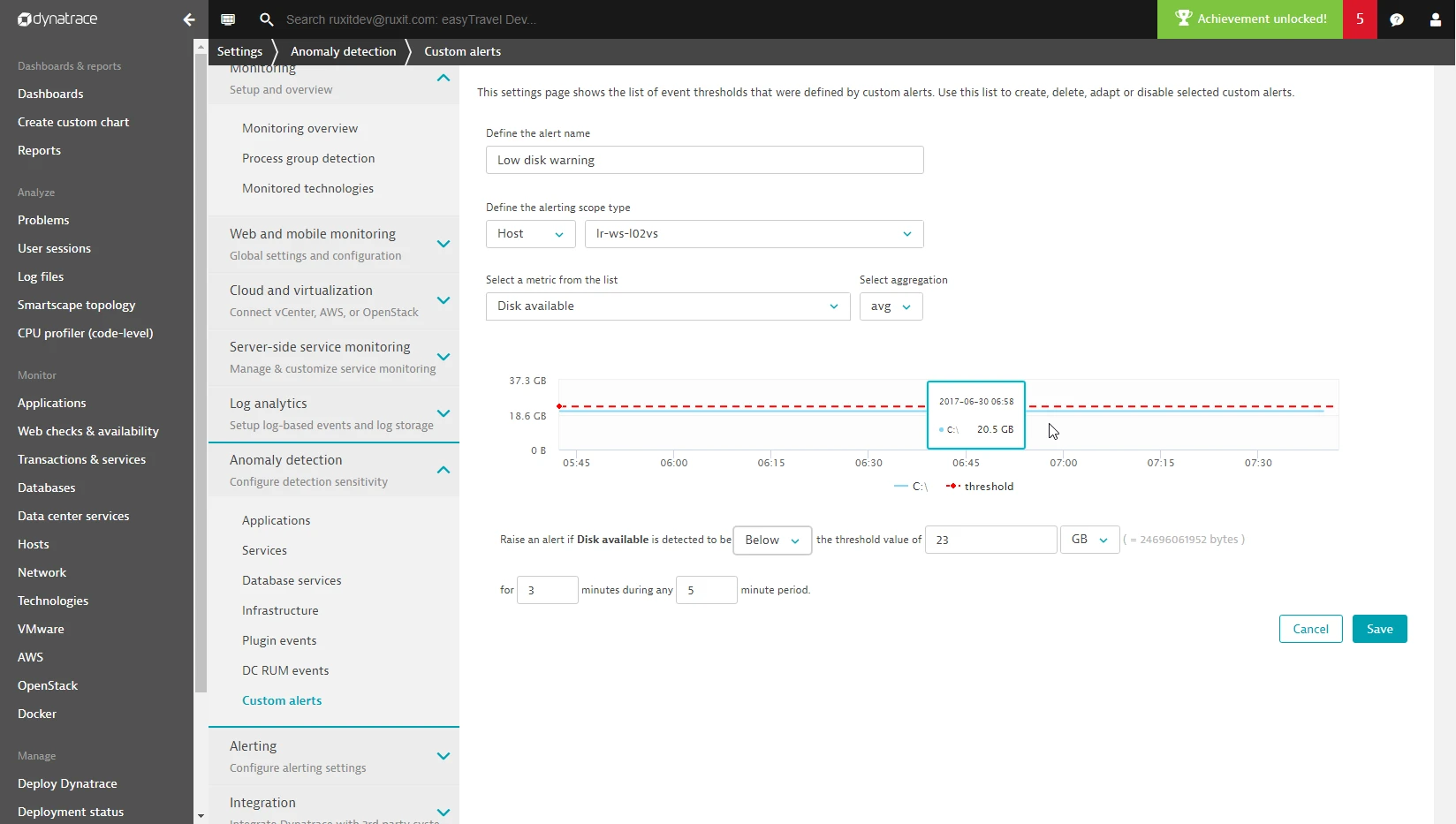
How polling intervals affect detection
For observability tools, the polling interval significantly impacts detection speed and issue management. For example, a 5-minute polling interval in Datadog could allow issues like CPU spikes or memory leaks to develop and worsen before a team is even notified. Feedback from users on platforms like Reddit reflects that delayed alerts can result in extended troubleshooting times and an increased risk of service degradation, especially for fast-growing issues.
Is it just me, or datadog alerting is super slow
byu/pojzon_poe indevops
Middleware is a full-stack cloud observability platform designed to meet the needs of today’s dynamic, high-demand infrastructure environments. As a recent entrant to the market, it offers a near real-time alerting system that departs from traditional polling-based models.
Unlike Datadog, New Relic, and Dynatrace, which operate on longer polling windows, Middleware provides rapid, continuous data analysis. This approach allows alerts to be sent the moment an anomaly is detected, offering businesses a proactive way to tackle issues before they escalate.
Middleware’s key differentiator is its ability to deliver instantaneous insights and real-time notifications without the limitations of traditional polling intervals. This ensures faster detection, quicker response times, and more control over system performance. By reducing the lag between detection and alerting, Middleware helps teams stay ahead of potential issues and protect vital systems from unexpected downtime.
Editor’s Pick: This 2-Year-Old Startup is Drawing Customers Away from Datadog & New Relic
Exploring Middleware’s real-time alerting capabilities
Middleware offers a real-time alerting system that allows organizations to monitor key metrics and receive notifications as soon as an anomaly is detected.
While the configuration steps may evolve, the core functionality of Middleware ensures that businesses can track system performance and detect issues with minimal delay, making it highly efficient for critical services.
Overview of Middleware’s alerting system
Middleware’s platform is designed to help users set up alerts for various system metrics and any data that is sent to middleware (ex: metrics, logs, traces, custom metrics).
By using real-time data collection, Middleware detects anomalies and triggers alerts instantly, allowing teams to address issues before they escalate.
- Customizable Alerts: You can configure Middleware to trigger alerts based on specific thresholds. For example, if your CPU usage exceeds a certain percentage, an alert will be triggered, and teams will be notified immediately. Alerts can be tailored to specific needs, ensuring that your team gets relevant notifications.
- Alert Drill Down: A standout feature, alert drill-down lets users navigate to the root cause of an issue with just a few clicks. This functionality provides quick access to related data, such as logs, metrics, and traces, streamlining the troubleshooting process and accelerating issue resolution.
- Integrations: Middleware integrates with 200+ tools like Slack and PagerDuty to send alerts to your preferred communication channels. This ensures your team stays informed in real-time, wherever they are.
- Alert Fine-Tuning: Middleware provides features to help avoid alert fatigue. You can fine-tune alerting parameters to ensure that your team only receives notifications when a genuine issue arises, reducing unnecessary noise from alerts that are too sensitive.
- Performance Monitoring: The platform’s alerting system continuously monitors infrastructure performance, detecting anomalies such as CPU spikes, memory leaks, and disk bottlenecks. This continuous monitoring ensures that no issue goes undetected, helping businesses prevent downtime and maintain optimal service performance.
Observing metrics in real-time
Middleware’s intuitive dashboards make it easy to track performance metrics visually. Users can observe CPU usage trends, network traffic patterns, and system health metrics in real-time, making it easier to correlate system behavior with alerts. This visual representation of data enhances understanding and quickens the decision-making process.
For more information, Middleware provides documentation on setting up alerting configurations and using dashboards to monitor system metrics. You can explore detailed documentation on how to use the platform effectively for your monitoring needs.
Check it out: Middleware alerting setup
By utilizing Middleware’s near real-time alerting, organizations can dramatically improve their response times and mitigate risks of downtime by detecting issues as they happen.
Why short polling intervals matter for important services
When your system depends on real-time performance, even a 1-minute delay can be too long. Delayed windows, such as the 5-minute intervals used by Datadog, create a significant gap in which issues can go undetected. Platforms like Dynatrace and New Relic may offer shorter windows at 1 minute, but even then, the gap may still be too large for critical services.
Real-world impact of delayed alerts
Consider a scenario involving an e-commerce platform. A sudden CPU spike during peak traffic times could result in delayed page loads or transaction failures. With Datadog’s 5-minute delay, this issue could persist for several minutes before an alert is triggered, leading to lost sales and unhappy customers. Middleware’s real-time alerting minimizes this risk by ensuring faster detection and enabling teams to act immediately.
How Middleware’s real-time alerting protects your services
The main benefit of Middleware’s real-time alerting is the ability to reduce response time drastically. By detecting anomalies as they occur, it allows your team to respond before the situation worsens.
Example: CPU spike detection
Imagine your system experiences a sudden CPU spike. With Middleware, alerts are triggered almost instantly, allowing your team to address the issue proactively. In contrast, tools like Datadog with 5-minute intervals or even New Relic’s 1-minute intervals might leave the issue undetected for too long, leading to performance degradation.
Avoiding common pitfalls in monitoring
Relying on tools with longer polling intervals can lead to blind spots in your monitoring system, which in turn leads to delayed responses. This is particularly problematic in tools like Datadog, where users have reported slow alerting speeds on platforms like Reddit.
Common Pitfalls Include:
- Missed Spikes: A sudden CPU spike that occurs between polling windows may go unnoticed until it’s too late.
- Slow Response: The longer the polling interval, the longer it takes to trigger alerts, which slows down response times.
Middleware prevents these issues by continuously collecting and analyzing data, ensuring that alerts are sent in real-time, not delayed by a polling window.
Competitors vs. Middleware
Middleware: Near real-time alerting
This full-stack cloud observability platform provides near real-time alerting, continuously analyzing incoming data to detect and respond to issues as they arise. This proactive approach ensures teams are immediately notified of critical anomalies, reducing downtime and supporting uninterrupted service availability.
Datadog: 5-minute polling
Datadog’s default polling interval is 5 minutes for many integrations, such as AWS metrics. While effective for broader monitoring, this interval can delay detection of rapidly evolving issues, as noted by users on Reddit who report delays in critical alerting during high-stakes incidents.
New Relic: 1-minute polling
New Relic typically uses a 1-minute polling interval, which balances frequency with system load across many integrations, such as those for AWS. This interval provides timely monitoring, yet can still lead to delayed alerts in environments requiring immediate response.
Dynatrace: 1-Minute Polling
Dynatrace’s OneAgent also defaults to a 1-minute interval, similar to New Relic, providing frequent updates on application and infrastructure metrics. However, as discussed in the Dynatrace community, this interval may not meet the needs of time-sensitive systems that require immediate detection.
Why Middleware stands out
Middleware’s near real-time alerting offers an operational advantage for teams needing faster detection and response. Unlike traditional delayed polling intervals, it provides timely notifications that allow users to tackle issues before they escalate. This makes Middleware an optimal choice for critical environments where every second counts.
Real-time alerting: The backbone of modern infrastructure
In environments where uptime, rapid response, and reliability are non-negotiable, real-time alerting is critical. Traditional tools like Datadog, New Relic, and Dynatrace, while powerful, often rely on delayed polling intervals, which can slow down detection, leaving businesses vulnerable to avoidable outages.
The limitations of delayed alerting systems were evident in incidents like the recent CrowdStrike outage, underscoring how essential real-time alerting is for quick, proactive responses.
Middleware’s near real-time alerting offers a new approach, empowering teams to detect and act on issues as they arise—minimizing downtime and ensuring optimal system performance. With Middleware, teams gain the advantage of timely notifications, reducing service interruptions, enhancing customer experience, and preserving business continuity.
Ready to see the difference Middleware can make for your infrastructure?
Explore Middleware’s alerting capabilities and discover how real-time insights can drive efficiency, resilience, and reliability in your operations.
What is the significance of real-time alerting in critical services?
Real-time alerting empowers teams to respond immediately to issues, preventing minor problems from escalating into significant disruptions and minimizing downtime.
How do polling intervals impact detection speed?
Polling intervals significantly impact detection speed. Longer intervals can delay issue detection, increasing the risk of downtime and user dissatisfaction.
What is Middleware's polling interval for alerting?
Middleware offers near real-time alerting with a 15-second polling interval, allowing for instantaneous insights and notifications.
How does Middleware's alerting system differ from competitors like Datadog, New Relic, and Dynatrace?
Middleware provides near real-time alerting, whereas competitors have longer polling intervals (e.g., Datadog’s 5-minute, New Relic’s 1-minute, and Dynatrace’s 1-minute intervals).
What are the benefits of using Middleware's real-time alerting?
Benefits include faster detection, quicker response times, reduced downtime, enhanced customer experience, and preserved business continuity.
Can Middleware's alerting system be customized?
Yes, Middleware allows users to configure alerts based on specific thresholds, fine-tune alerting parameters, and integrate with tools like Slack and PagerDuty for seamless notification.



