
What is alert fatigue?
Alert fatigue refers to a situation where one becomes desensitized to alerts and overlooks them due to their overwhelming frequency. This surplus of alerts may result in delayed responses or total non-responsiveness, and the consequences can critically impair operational effectiveness and compromise security.

For instance, a single disruptive alert while they’re engrossed in their work isn’t a major inconvenience and is easily managed and dealt with. But what when these alerts exponentially increase? If the employees suddenly have to jostle with a dozen abrupt interruptions, it can be overwhelming.
The stakes rise exponentially in large IT infrastructures where alerts can reach sky-high numbers. In such scenarios, the probability of missing out on vital alerts is dangerously high.
- The prevalence of false alarms adds to the burden. Research points to 72 – 99% of all clinical alarms being false alarms in the healthcare industry.
- In the tech industry, a comprehensive survey showed 52% of all alerts to be false, with a further 64% identified as redundant.
A vast number of false alerts often lead to a conditioned dismissive response from professionals, as they begin to view most alerts as false positives. This can trigger a chain reaction of negative effects on operational efficiency and overall security of the organization.
What causes alert fatigue?
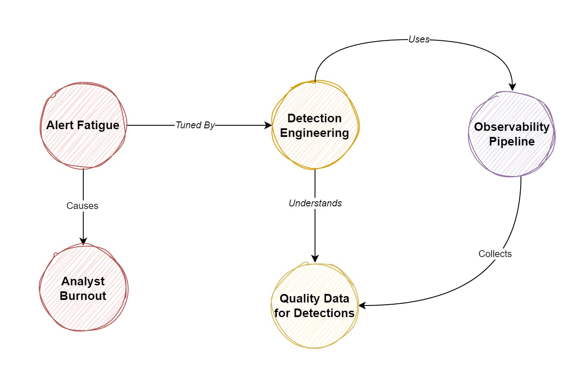
Alert fatigue is not a result of a singular issue but is caused by several interconnecting factors. The following are key reasons that contribute to alert fatigue:
Overabundance of alerts
The prevalence of alert fatigue often stems from an excessive number of alerts flooding an IT operator’s system. This frequency tends to overwhelm the operator, causing crucial notifications to be lost in the sea of accumulated alerts. The sheer magnitude of these alerts can instigate a desensitization toward recognizing genuine threat alerts.
Let’s envision a situation where your server, due to a minor issue, triggers ten identical alerts within five minutes. As the issue persists, so do the notifications, leading to a swell in alerts that become challenging to address.
This stream of messages soon transforms into alert fatigue, obstructing the DevOps team from noticing or acting upon other significant and potentially threatening alerts. This is an instance of alert flooding, a key contributor to IT alert fatigue.
Lack of alert prioritization
When you’re overburdened with alerts, it becomes exceedingly difficult to discern which alerts are genuinely critical and which can be momentarily shelved. This is where alert prioritization standpoints fall.
Adequate alert prioritization is essential for effective system management and smooth IT operations. It primarily involves setting essential thresholds and using sophisticated alert conditions to ensure that only the most pertinent alerts are escalated.
For instance, let’s consider a hypothetical e-commerce platform. The priority of alerts should reflect the potential business impacts. An alert associated with a failure in the payment system should be considered a high-priority issue because it directly interrupts revenue generation.
However, an alert about a non-responsive link in a less trafficked blog post on the same site might be marked as a lower priority. Noticing and addressing alerts based on their effect on the business enterprise thus contributes to more efficient incident management.
Noise from non-actionable alerts
Non-actionable alerts are a significant contributor to alert fatigue. This term refers to those alerts which neither require immediate attention nor any subsequent action.
These noise alerts may not signal an actual issue, becoming no more than a distracting background noise for the IT and DevOps personnel. Over time, they become almost invisible, causing more critical, actionable alerts to be missed. This subsequently leads to a rise in IT alert fatigue.
For instance, consider a system in which redundant notifications are generated for minor deviations in network bandwidth usage. Though these fluctuations may be within acceptable thresholds, they trigger continual alerts, contributing to the overall noise.
This frivolous ‘alert storm’ not only dilutes the importance of genuinely critical alerts but also perpetuates and aggravates alert fatigue among DevOps teams.
Inadequate alert sensitivity
Alerts can be configured with varying sensitivity levels. Inadequate alert sensitivity occurs when these levels are not properly established, leading to a bombardment of trivial alerts that drown out the ones that truly matter.
This situation can cause IT alert fatigue, as teams may begin to disregard notifications due to their overwhelming volume.
Consider a scenario where an application’s CPU usage surges above 50%. If set too sensitively, an alert may trigger for this non-critical event, overshadowing more crucial alerts, such as a database nearing full capacity.
The inundation of minor alerts can desensitize engineers to notifications, leading to overlooked critical alerts and resultant IT alert fatigue.
Knowing what causes alert fatigue is the first step to tackling it. By addressing these aspects, organizations can start developing a more effective alert management strategy to reduce alert fatigue and increase the effectiveness of their DevOps teams, safeguarding the performance and integrity of their IT systems.
Signs of alert fatigue
Understanding and identifying the early signs of alert fatigue within your IT team is essential to prevent a decrease in productivity or missed critical alerts. This comprehensive rundown will zero in on key indications that you might be experiencing IT alert fatigue. Arm yourself with this knowledge to foster a healthier, more effective technology environment.
Slow response to notifications
When teams constantly endure an influx of alerts, critical or not, their response time inevitably slows down. This phenomenon, often referred to as alert saturation, hampers the ability of IT professionals to isolate significant alerts promptly.
Analyzing the noise-to-signal ratio could provide insight into whether alert volumes are aligning with the capacity to address them. This reflects alert fatigue and its impact on operational efficacy.
Over time, the resultant delays can escalate into serious complications, affecting both system performance and customer satisfaction.
- Analysis: Regular monitoring of response times aids in gauging the severity of alert fatigue.
- Signal-to-noise ratio: Keep a check on the proportion of meaningful to meaningless alerts. A high ratio indicates an overabundance of non-actionable alerts.
- System performance: Prolonged delays due to slow response can significantly affect system stability.
- Customer satisfaction: Inevitably, system performance issues can lead to end-user dissatisfaction.
Ignoring or missing important alerts
Alert fatigue can be a significant issue, leading to oversight of important alerts. A particular symptom of alert fatigue is when DevOps professionals, inundated by a large volume of alerts, begin to ignore or miss critical notifications.
This happens when the frequency of alerts is so high that they become indistinguishable from one another. Consequently, IT personnel might overlook an alert containing crucial information, thereby putting systems at risk.
- The volume of alerts can overwhelm IT personnel, making it impossible to distinguish between trivial and important alerts.
- IT personnel may ignore critical alerts due to alert desensitization caused by excessive alert exposure.
- Unresolved alert fatigue can lead to a delay in identifying and resolving system issues.
Frustration about receiving a new alert
The continuous barrage of notifications can easily lead to frustration, especially when the alerts lack actionable data or context. This scenario often stemmed from an improperly managed alert system. Resolving this issue necessitates the adjustment of alert frequency and sensitivity, coupled with effective prioritization strategies.
- Frustration with new alerts: Continued sense of irritation or dread when new alerts arrive.
- Source of the problem: Frequently due to poorly managed alert systems.
- Excess notification: A barrage of alerts may overwhelm the recipient, leading to dismissiveness or desensitizing them to the importance of these warnings.
- Need for actionable data: Alerts often ignite frustration when they lack actionable insights or relevancy, rendering them mere disturbances.
- Solution: Addressing this issue requires ameliorating alert management, frequency, and overall system sensitivity, along with implementing effective prioritization strategies.
Lack of breaks between alerts
When dealing with the complexity of modern IT environments, the lack of breaks between alerts can throw teams into a constant state of high-stress vigilance. A barrage of alerts, one after another, often leads to an overwhelming sentiment, hampering the ability to focus on critical tasks.
- Continuous Alerts: The incessant inflow of alerts from various monitoring tools makes it impossible for engineers to prioritize crucial issues.
- No Respite: The absence of well-defined alert cycles can impede the teams’ efficiency, affecting the overall productivity of DevOps engineers.
- Effectiveness Reduction: Without appropriately spaced alerts, teams may miss out on hidden dependencies or more profound systemic issues within the tech stack.
Inability to prioritize alerts
When inundated with alerts, IT teams may struggle to segregate high-priority issues from non-urgent ones, resulting in a common symptom of alert fatigue known as the inability to prioritize alerts. In essence, every alert begins to seem equally important or, conversely, equally unimportant.
- Alert prioritization issues can occur when an overwhelming volume of alerts regularly floods the IT environment, reducing the distinction between risk levels.
- The increased risk of overlooking critical alerts can lead to delayed resolution of serious issues, negatively impacting system performance and user experience.
Burnout
When dealing with alert fatigue, burnout is a critical concern that one shouldn’t overlook. It’s a condition of complete mental, emotional, and physical exhaustion usually brought on by prolonged or repeated stress, particularly when the individual feels overwhelmed or out of control.
IT alert fatigue contributes significantly to this sensation, as the continuous inflow of non-stop alerts tends to stretch IT personnel beyond their stress thresholds.
- It’s marked by an individual feeling disillusioned, frustrated, and less productive.
- Employees may feel devalued when they’re routinely interrupted or pulled away from innovative work to attend to relentless alerts.
- Severe burnout can lead to health problems, including depression, heart disease, and diabetes.
Therefore, DevOps teams must have strategies in place to tackle alert fatigue, prevent burnout, and ensure teams remain productive and motivated.
Best practices to prevent alert fatigue
The disruptive wave of alert fatigue can potentially wreak havoc on any IT setup. The good news is that it’s not an invincible enemy and can be tackled effectively.
Let’s look at some of the strategies you can effectively implement to tackle the root cause of alert fatigue successfully.
Set tiered alert priorities
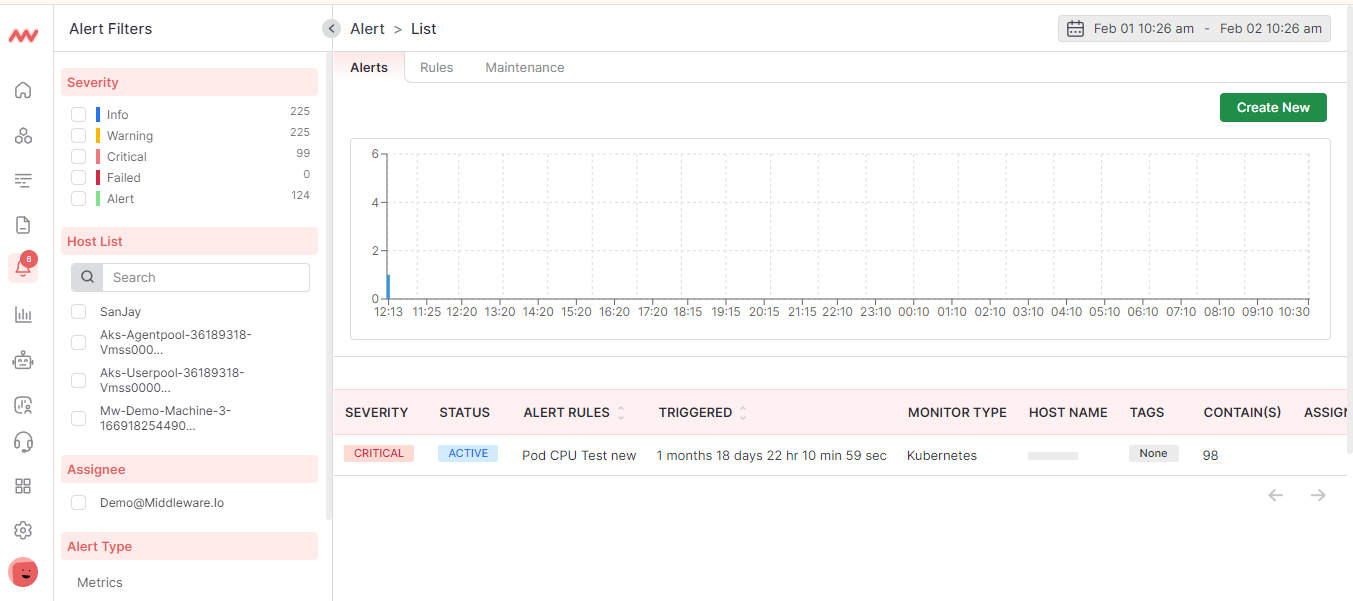
Setting up a tiered alert system is paramount to steer clear of IT alert fatigue. This approach implies categorizing alerts based on their urgency so that your team can immediately distinguish between critical issues and minor glitches.
To implement this, define your tiers clearly and provide accurate descriptions. It could be as simple as three-tier systems, which may include ‘critical,’ ‘warning,’ and ‘information.’ which can easily be done with tools like Middleware.
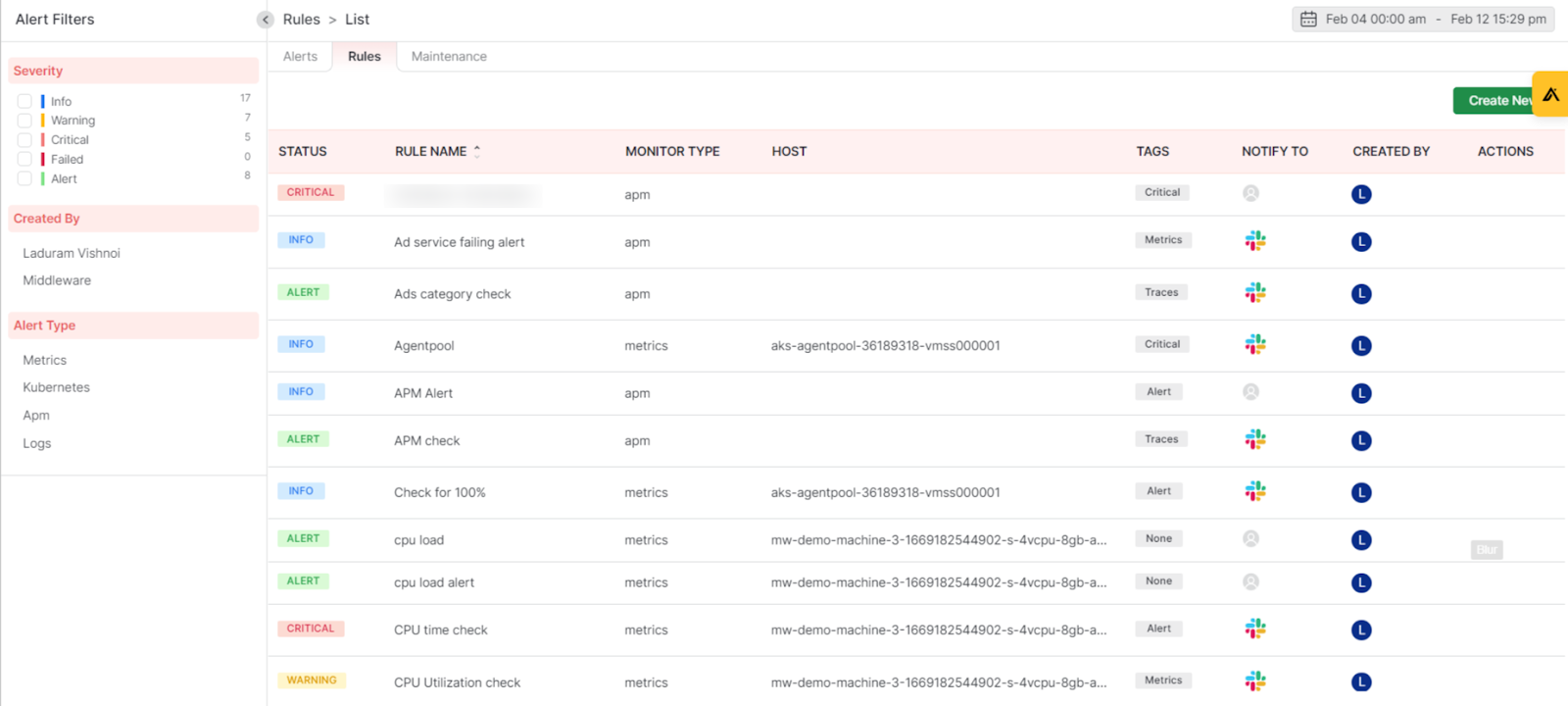
Utilizing an AI-powered alert system like Middleware reduces alert fatigue and downtime by promptly responding to potential and actual infrastructure errors.
Keep in mind:
- Prioritize alerts based on the impact on the system or customer experience.
- Review your tiers regularly and adjust as your system’s environment evolves.
- Make sure necessary staff members are trained and informed about the tiered alert system.
Adhere to on-call schedules
Strict adherence to on-call schedules can help alleviate IT alert fatigue. This means that there is a clear rotation of team members who are responsible for responding to alerts at given times. This method helps to prevent burnout and increases the morale of the team.
Here are a few points to keep in mind:
- Each team member should know their on-call schedule in advance. This reduces confusion and ensures everyone is prepared.
- Keep shifts reasonable and fair. Overworking only one or two team members can lead to fatigue and possibly even burnout.
- Rotate on-call responsibilities regularly. This prevents burnout and keeps all team members equally experienced.
Keep alerts actionable
Ensuring that alerts are actionable goes beyond simply addressing an issue; it includes the context and the next steps that need to be taken. A worthwhile alert leads DevOps engineers to troubleshoot links, log snippets, and correlated insights that offer a clear action path.
For instance, rather than receiving an ambiguous “Server error detected” message, a better route would be: “Server error detected in Service XYZ. CPU usage exceeded 80% over the past 15 minutes. Consider increasing your server capacity.”
- Define clear actions that should follow an alert.
- Back up every alert with context and correlated data.
- Focus on alerts that require immediate attention and intervention.
Consolidate redundant alerts
One colossal contributor to IT alert fatigue is the barrage of surplus alerts, often coined as “noise.” These are frequently a consequence of redundant warnings triggered by identical or interrelated events in the system.
- To mitigate this, consolidate alerts originating from the same root cause into singular, significant alerts. This action not only tidies up your alert interface but substantively reduces noise for your DevOps team.
- The application of algorithmic correlation logic can prove extremely valuable in identifying and consolidating echo alarms, thereby maintaining an impeccably clean alert inventory.
- Leveraging modern Alert Management Systems (AMS), such as ones provided by Middleware, designed to weed out duplicate and redundant alerts, can significantly decrease the deluge and enhance your team’s response time.
Consolidate information
Consolidating information is a vital measure to avoid IT Alert Fatigue. This practice involves gathering data from different sources and then streamlining it into one unified view, which greatly reduces the potential for alert overload.
It entails the use of robust IT monitoring tools capably designed to effortlessly assimilate vital system alerts, messages, and updates in one centralized hub. Benefits of this approach include:
- Ensuring that vital alerts don’t get lost in the noise owing to being spread across numerous channels or platforms.
- Providing a comprehensive overview of all system warnings for structured analysis and swift resolution. Root cause analysis is key here. On a robust platform like Middleware, you can view all details associated with an alert, like metrics and logs, for a faster identification of the root cause.
- Boosting DevOps teams’ efficiency and responsiveness by minimizing distraction and time required to scan multiple alert sources. Fostering this consolidation habit can prove key to staying afloat in the deep sea of routine system notifications.
Preventing alert fatigue requires strategic planning, effective execution, and continuous monitoring. The steps above can serve as strong pillars in building an alert, fatigue-resistant workspace and cultivating a healthier and more productive IT environment. A proactive approach is always better than a reactive one.
Using Middleware to Avoid Alert Fatigue
The digital landscape is ever-evolving, and the demand for advanced technologies that ensure maximum productivity while reducing excessive alerts for IT teams is paramount.
Middleware represents such a technology, serving as a vital link, orchestrator, and manager among various applications and software. It facilitates a more efficient DevOps environment. A standout feature of Middleware is its effective alert module.
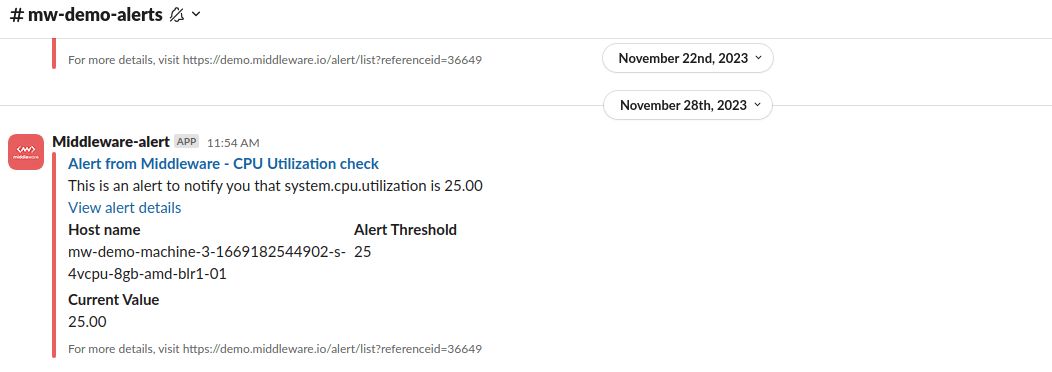
The alert module of Middleware primarily classifies alerts into low, medium, and high-priority levels. This classification eases the engagement process, allowing DevOps teams to concentrate on the most pressing issues.
Actionable alerts, automatic root cause analysis for each, and more make Middleware an essential tool to mitigate alert fatigue and promote a proactive approach within DevOps teams.
Middleware also gives a correlation of data to pinpoint root cause faster, hence, with the effective use of tools like Middleware and its alert module, tech leaders, IT managers, and DevOps engineers can manage and prioritize notifications effectively.



