Serverless Architecture, also known as serverless computing, has garnered significant attention in recent years due to its agility, flexibility, and cost-effectiveness.

The global serverless architecture market is projected to grow at a ~25.70% CAGR from 2023 to 2035. The market is poised to generate revenue of USD 193.42 billion by the end of 2035, up from USD 12.43 billion in 2022.
Serverless has moved beyond a trend in 2026, it powers thousands of production systems. According to Datadog’s Serverless Report, AWS Lambda use has grown by more than 100% YoY, while enterprises increasingly migrate microservices to FaaS for cost control and auto-scaling. Serverless appeals to startups and large enterprises alike because it reduces infrastructure decisions and accelerates development cycles.
But what does this term mean? How does it specifically benefit developers? Most importantly, where is it best suited for enterprise applications?
This comprehensive guide will delve into understanding the nuances of serverless architecture, exploring its trends, benefits, challenges, use cases, and providing insights into efficient utilization for software development.
What is Serverless Architecture?
Serverless architecture is a cloud-native execution model where the cloud provider manages infrastructure, autoscaling, availability, and capacity planning. Developers only deploy functions or event-driven components — paying strictly for execution time.
In a serverless model, developers only package code and let the cloud provider handle provisioning, scaling, patching, routing, and availability. Instead of paying for servers or VMs, you pay only when your function runs. This eliminates idle capacity costs, which is why companies with spiky workloads prefer serverless.
For example, an e-commerce app may experience sudden traffic spikes during flash sales; serverless scales up instantly without manual intervention.
While your application still runs on a server, the cloud provider handles all server management and infrastructure tasks, such as provisioning servers, managing operating systems, and allocating resources.
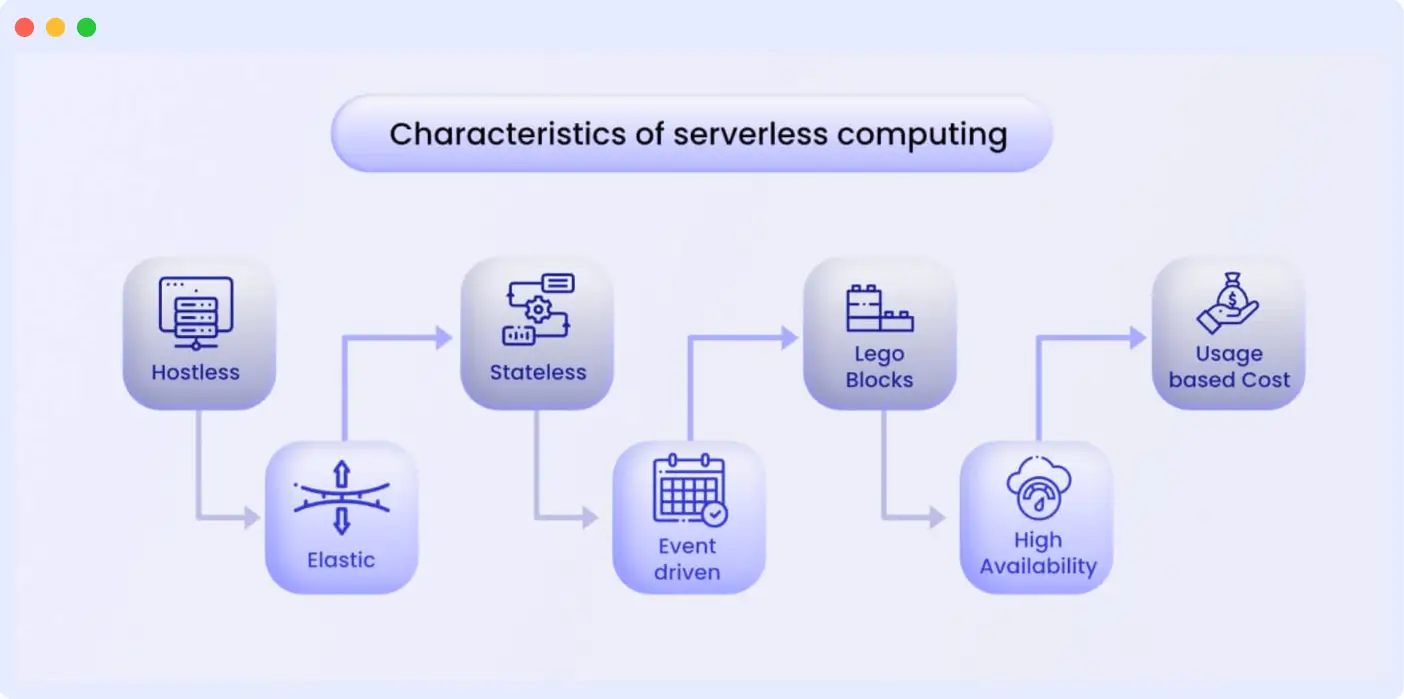
Consequently, developers can write and deploy code without having to manage computing resources or servers.
Serverless architecture helps organizations eliminate the need for expensive traditional servers. This revelation opens new possibilities in application development and scalability by eliminating the need for server management, enabling automatic scaling, and reducing operational overhead.
It evolves from data centers, virtual machines, and Elastic Compute Cloud (EC2) to usher in the era of serverless computing.
The heightened demand and the simplicity it offers have encouraged major technology giants Amazon, Google, and Microsoft to invest heavily in a serverless architecture.
Serverless Architecture Components
A complete serverless system includes:
1. Compute Layer (FaaS): AWS Lambda, Azure Functions, Google Cloud Functions.
2. Event Sources: API Gateway, CloudWatch Events, database triggers, storage events.
3. API Gateway Layer: Routes requests to serverless functions.
4. Data Services: DynamoDB, Firestore, CosmosDB for persistent storage.
5. Orchestration: Step Functions, Azure Durable Functions, Cloud Workflows.
6. Observability Layer: Tools like Middleware, Datadog, New Relic for logs, metrics, tracing.
Modern serverless apps are built as distributed event-driven workflows rather than single functions, enabling low latency and rapid scale-out.
Serverless Architecture in 2026: Key Trends Shaping Adoption
1. Edge Serverless Functions: Providers like Cloudflare Workers and AWS Lambda@Edge push compute close to users, enabling ultra-low-latency workloads such as personalization, A/B testing, and real-time security checks.
2. Reduced Cold Start Times: Cloud providers now offer “provisioned concurrency” and “always-warm execution pools,” lowering cold starts by ~60–80% for latency-sensitive apps.
3. Serverless + AI: Serverless functions increasingly power ML inference, automated retraining triggers, and lightweight ETL jobs.
4. Serverless Containers: Tools like AWS Fargate and Google Cloud Run blur the line between containers and serverless, enabling longer execution times and more complex apps.
5. Enterprise adoption is accelerating: Finance, healthcare, media, and IoT companies now run entire pipelines on serverless due to lower operational burden and predictable scaling.
Fundamental Terms in Serverless Architecture
In Serverless Architecture, understanding specific fundamental terms is crucial as they shape the framework for grasping the dynamics and functionality of serverless systems. These key terms play a significant role in defining the structure and operation of serverless computing:
- Invocation: Represents a single-function execution.
- Duration: Measures the time taken to execute a serverless function.
- Event: Triggers the execution of a function originating from various sources like HTTP requests, database changes, file uploads, timers, or external services, making Serverless applications event-driven.
- Stateless: Denotes functions that do not maintain state or memory between invocations, allowing for easy scalability and distribution.
- Cold Start: Describes the delay during the initial invocation or after a period of inactivity, resulting in longer response times compared to “warm” executions.
- Warm Execution: Refers to a function already invoked with allocated resources and an initialized runtime environment, leading to faster execution.
- Concurrency Limit: Specifies the number of instances running simultaneously in one region, determined by the cloud provider.
- Orchestration: Involves coordinating the execution of multiple functions or microservices to manage complex workflows or business processes.
- Function-as-a-Service (FaaS): Serves as a core component of Serverless Architecture, where individual functions are the primary units of execution, responding to events or triggers written by developers.
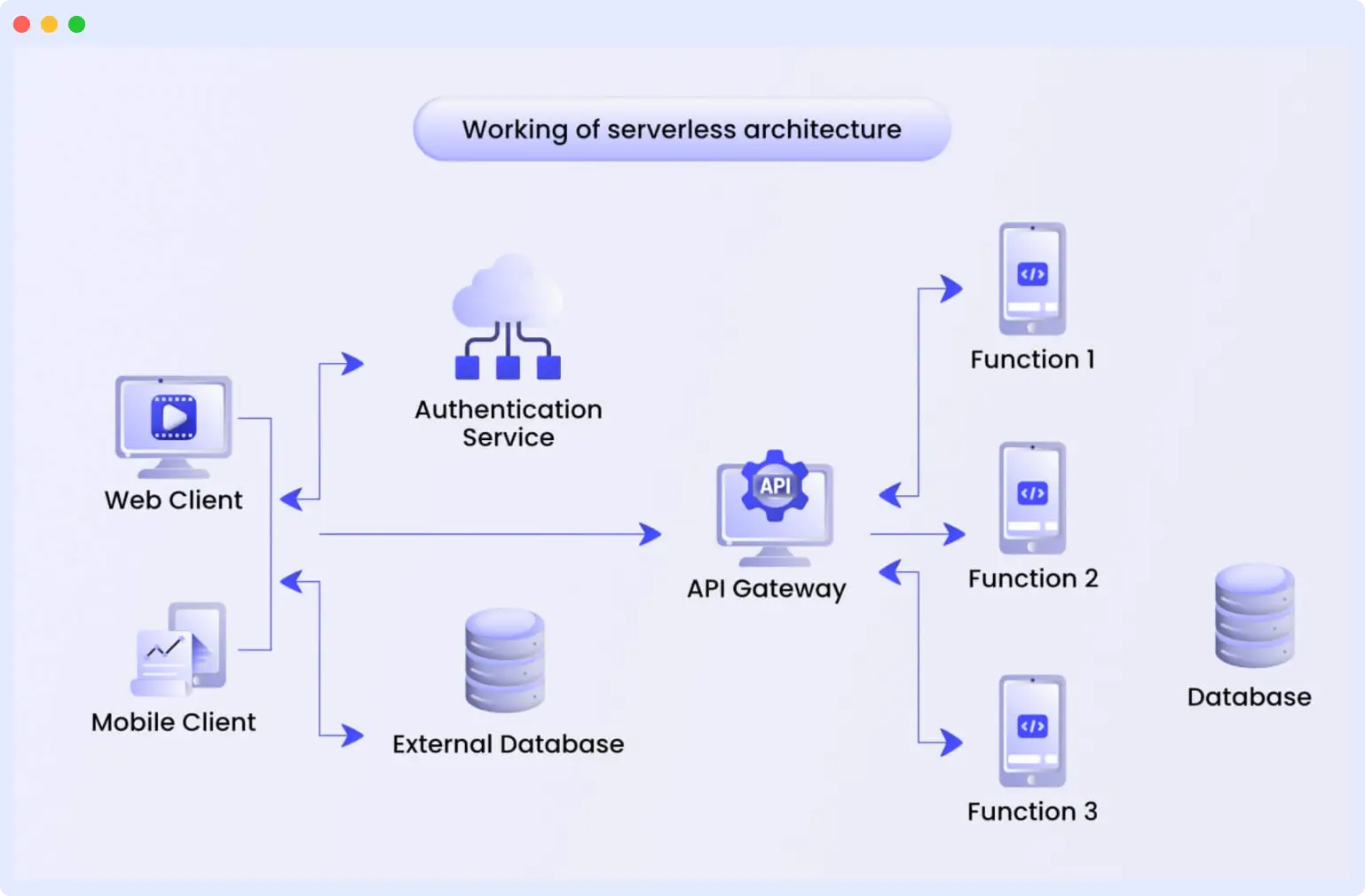
How Serverless Architecture Works
Now that we understand Serverless Architecture and its common terminologies, let’s delve deeper into how it works.
Serverless systems are designed to execute specific functions, which are offered by cloud providers as part of the Function-as-a-Service (FaaS) model. The process follows these steps:
- Developers write application code for a specific role or purpose.
- Each function performs a specific task when triggered by an event. The event triggers the cloud service provider to execute the function.
- If the defined event is an HTTP request, it is triggered by a user’s actions, such as clicking or sending an email.
- When the function is invoked, the cloud service provider determines whether it needs to run on an already active server. If not, it launches a new server.
- Once this is complete, the user will see the output of the function.
These execution processes operate in the background, allowing developers to write and deploy their application code.background, allowing developers to write and deploy their application code.
Benefits of Serverless Architecture
Serverless Architecture’s adoption in organizations is on the rise. According to the 2022 State of Serverless report, 70% of AWS customers, 60% of Google Cloud customers, and 49% of Azure customers are currently utilizing serverless solutions. Some top benefits include:
- Reduced Operational Overhead: Serverless abstracts infrastructure management, freeing developers from concerns related to server provisioning, maintenance, and scaling. This allows teams to focus on writing code and delivering features.
- Scalability: Serverless applications automatically scale up or down based on the incoming workload, ensuring they can handle fluctuating traffic without manual intervention.
- Cost Efficiency: Pay-as-you-go pricing means payment is only for the resources consumed during function executions. There are no ongoing costs for idle resources, making it cost-effective, especially for sporadically used applications.
- Rapid Development: Serverless promotes quick development and deployment. Developers can write and deploy functions swiftly, allowing for faster time-to-market for new features or applications.
- Granularity: Functions in Serverless applications are highly granular, enabling modular, maintainable code. Each function focuses on a specific task or service.
- Event-Driven Flexibility: Serverless is well-suited for event-driven applications, making it ideal for use cases such as real-time analytics, chatbots, IoT solutions, and more.
- Improved resilience: Serverless functions run across multiple availability zones by default. This reduces the risk of single-point failures and improves uptime.
- Performance efficiency: Since functions scale instantly, serverless can handle sudden 10x–50x spikes without manual actions.
- Lower total cost for bursty workloads: According to AWS, businesses save up to 70% when switching from provisioned EC2 instances to Lambda for spiky workloads.
Challenges of Serverless Architecture
While Serverless offers numerous advantages, it comes with challenges. Some of the most significant limitations of Serverless Architecture include:
- Vendor Lock-In: Serverless platforms are typically offered by specific cloud providers, making it difficult to switch providers without significant code changes, resulting in vendor lock-in.
- Limited Function Execution Time: Serverless platforms impose execution time limits on functions, typically ranging from a few seconds to a few minutes. This constraint can be challenging for long-running tasks.
- Debugging Complexity: Debugging and monitoring functions in a Serverless environment can be more complex than in traditional applications, requiring specialized tools and approaches.
- Potentially Higher Costs: While Serverless can be cost-effective for many use cases, it may result in higher costs for applications with consistently high and predictable workloads. In such cases, traditional server infrastructure is preferred.
- Complex Architecture: As functions multiply, managing event-driven flows, retries, dependencies, and timeouts becomes more difficult without proper orchestration tools like AWS Step Functions.
- Observability Gaps: Traditional APM tools struggle in distributed, short-lived serverless systems. Developers require platform-native monitoring to trace cold starts, timeouts, and function failures.
Serverless Architecture Use Cases
1. Real-Time Data Processing
Serverless becomes the go-to choice for applications relying on real-time data processing due to its ability to add value in several ways:
- Log Analysis: Serverless functions process log data as it generates, enabling real-time analysis and alerting for issues or trends.
- Event Streaming: Serverless platforms like AWS Lambda seamlessly integrate with event streaming services, simplifying the process of processing and reacting to data streams from various sources.
- Custom Analytics: Serverless enables the performance of custom data analysis, empowering organizations to derive insights and make real-time decisions.
2. Event-Driven Applications
Serverless Architecture’s event-driven nature makes it an excellent choice for applications that rely on real-time processing and reacting to events. Here’s how it adds value:
- IoT Data Processing: Serverless functions can process data from IoT devices, such as sensor readings, and trigger actions based on that data.
- Real-Time Analytics: It enables real-time analytics by processing streaming data and generating insights or visualizations.
- Chatbots and Virtual Assistants: Event-driven Serverless functions can handle user interactions and external events, providing quick responses to queries or actions.
- Notifications and Alerts: Serverless can generate and send real-time notifications and alerts based on specific triggers or thresholds.
- Scalability: With event-driven applications, it automatically scales up or down to handle varying event loads.
⚡Try Serverless Monitoring for Free
Understand how your serverless functions behave under load. Run real-time traces, logs, and metrics in one place, free trial available.
3. Building APIs
Serverless is a potent choice for crafting APIs, especially for applications with modular and granular requirements. These applications can include the following:
- API Endpoints: Each Serverless function can specifically serve as an API endpoint, simplifying the development, deployment, and maintenance of APIs.
- Microservices: Serverless functions can function as microservices, handling distinct tasks, data processing, or database operations.
- Authentication and Authorization: Serverless functions can execute authentication and authorization logic to secure API endpoints.
- Custom Business Logic: Serverless APIs enable the implementation of custom business logic to enhance data processing and access control.
- Scalability: Serverless API endpoints can seamlessly scale to accommodate increasing API traffic.
Tools That Support Serverless Architecture
Having the right tools is pivotal for success in any technology ecosystem. This section will introduce you to the essential tools and services that support Serverless Architecture.
Middleware
Middleware is an end-to-end monitoring and observability solution that offers complete visibility for serverless applications. It features a unified dashboard for all your serverless applications, assisting you in monitoring and detecting anomalies, outliers, and forecasting for your entire serverless applications.
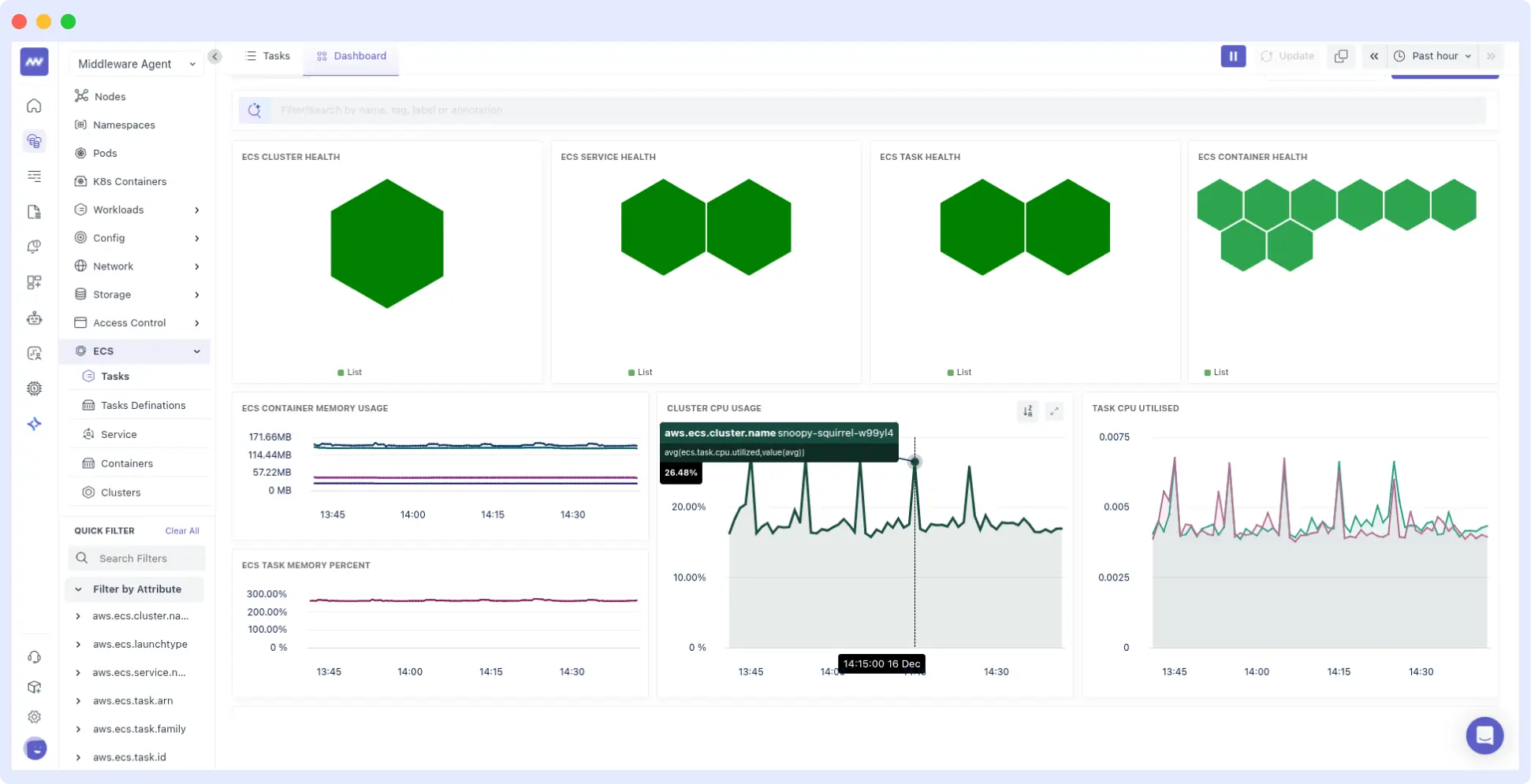
Middleware serverless monitoring provides observability for serverless applications such as AWS Lambda and Azure Functions, tracking metrics, traces, and logs across distributed, ephemeral workloads.
Middleware has evolved beyond standard dashboarding to provide an AI-powered observability layer. It goes beyond “showing” logs to “solving” bottlenecks.
Real-Time Cost Attribution: Monitor your cloud spend at the function level. Middleware correlates execution time with actual billing metrics, helping teams identify “runaway functions” before they impact the monthly budget.
AI-Driven Root Cause Analysis: Middleware’s AI engine automatically links API Gateway errors to specific cold starts or downstream database latency in DynamoDB, reducing MTTR (Mean Time to Resolve) by up to 90%.
Automated Distributed Tracing: Seamlessly track requests as they jump from SQS queues to Lambda functions and through Step Function orchestrations. Middleware provides a visual map of every event, eliminating “black boxes” in complex workflows.
Cold Start & Concurrency Intelligence: Gain granular visibility into cold start patterns. Middleware provides actionable recommendations on when to use provisioned concurrency to optimize user experience versus when to scale back to save costs.
👉To get started with automated instrumentation, follow the official Middleware docs:🔗Automatic Application Instrumentation
Datadog
Datadog is a tool that supports functional-level visibility, aiding in understanding serverless application health.
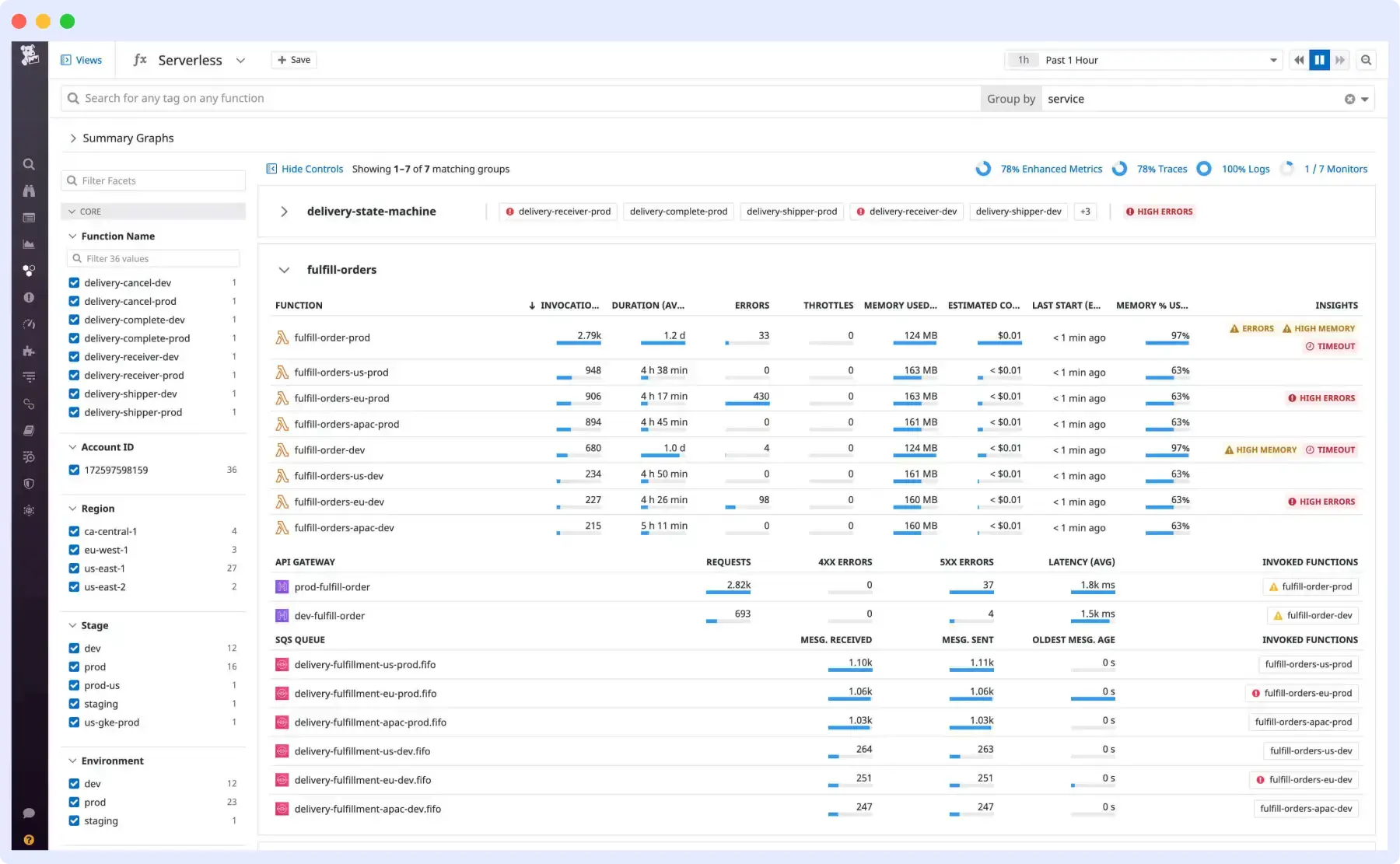
This tool consolidates all your functions in one place, enhancing the traceability of microservice calls across your stacks. Additionally, it provides monitoring, alerting, and visualization capabilities, enabling tracking of crucial performance and usage metrics in AWS Lambda.
🔍To understand Datadog’s serverless pricing and cost structure in detail, you can read our complete Datadog pricing breakdown.
New Relic
New Relic is an all-in-one monitoring tool that encompasses various functional areas, such as Serverless, Database, Cloud, Networking, Synthetic, and more.
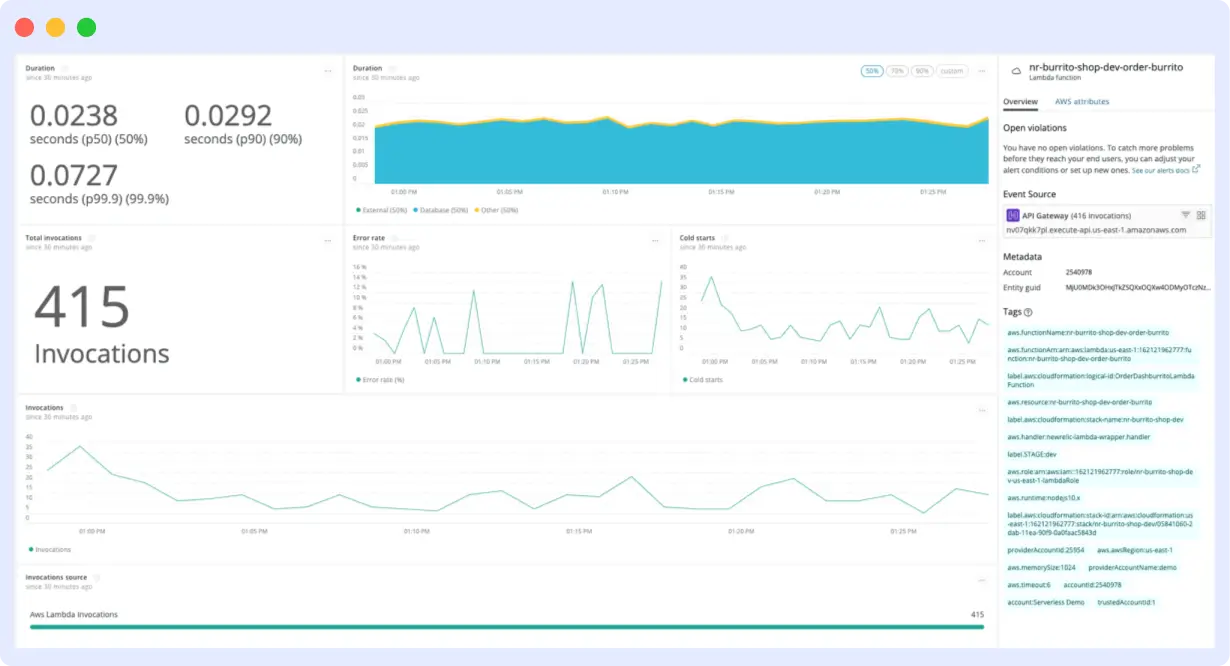
The serverless observability tool assists in seamlessly managing your cloud functions, including:
- Simplifying serverless functions to provide high-cardinality views of all requests and services.
- Providing alerts and troubleshooting for issues, allowing problems to be fixed before they impact users.
- Seamlessly tracking functions across AWS, Azure, or GCP.
👉 To understand New Relic pricing model, usage limits, and serverless cost structure, read our detailed New Relic pricing guide.
Serverless Architecture Examples
Serverless Architecture isn’t merely a concept; numerous companies and sectors already benefit from this technology.
Some of the most prominent examples of Serverless Architecture include:
Netflix Scalable On-Demand Media Delivery
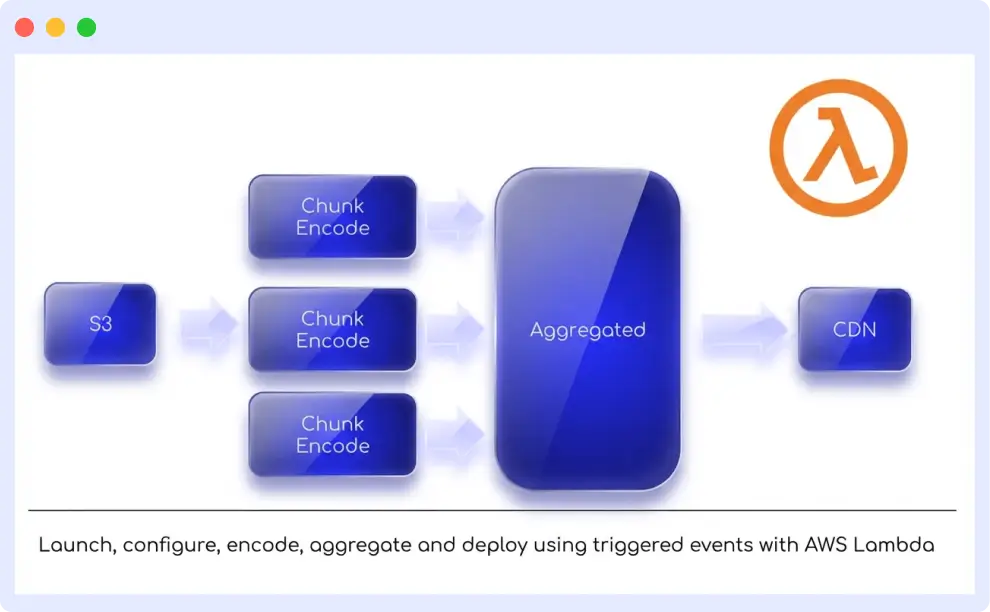
In 2017, Netflix began utilizing serverless computing to construct a platform for managing media encoding processes. Powered by AWS Lambda, Netflix developers only need to define the adapter code, determining each function’s response to user requests and computing conditions.
This approach aids Netflix in processing hundreds of files daily, ensuring smooth streaming without lags or system errors. Moreover, this architecture enables prompt alerts triggering and preventing unauthorized access, rendering it highly efficient for real-world usage.
Coca-Cola Vending Machine
It’s surprising to find Coca-Cola‘s name on the list, but the company was among the earliest to experiment with serverless technology for its vending machines. It began using it in its Freestyle machines, enabling customers to place orders, pay online, and receive their beverages.

Before implementing this technology, the company spent roughly $13,000 per year per machine, which was reduced to $4,500 annually. They are further enhancing the capabilities of their smart vending machines to handle 80 million monthly requests through fully immersive experiences.
Serverless Architecture vs. Container Architecture
Serverless and Container Architecture assists developers in deploying application code by abstracting away from the host environment. However, they exhibit subtle differences.
| Container Architecture | Serverless Architecture |
| It can operate on modern Linux and Windows systems. | Run on specific cloud platforms like AWS Lambda, Azure Functions, etc. |
| Can work with a local data center or developer workstation. | Not widely used outside of the Public Cloud Environment, as it is more challenging to implement. |
| Container engines and orchestrators are Open Source and can run in a local environment for free. | Charged as per usage in Public Cloud environments. |
| They are often stateless but can be configured to allow stateful applications. | Serverless Runtimes are built to accommodate stateless workloads and can provide data persistence by connecting to Cloud storage services. |
| Ideal for extended application. | Ideal for short-term usage, especially if there is an unexpected rise in activity. |
Serverless Architecture vs Microservices
Microservices and serverless represent distinct technologies that are closely related.
Microservices refer to the architectural pattern in which applications are divided into smaller services. These services, being small and independently deployable, collaborate to constitute an application.
Each microservice can be developed as a serverless function, simplifying the management and scaling of individual components.
Some subtle differences exist between these two technologies, including:
| Serverless Architecture | Microservices |
| Serverless abstracts away server management entirely. Developers focus on writing functions, and the cloud provider handles the underlying infrastructure automatically. | In a Microservices architecture, developers are responsible for managing the infrastructure on which services run. This includes provisioning servers, containerization, and orchestration. |
| Serverless functions are typically highly granular, performing specific tasks in response to events. They are stateless and ephemeral. | More extensive in scope compared to Serverless functions. Each microservice is typically responsible for a specific application component or feature. |
| They offer automatic and near-instantaneous scaling. They can handle a sudden influx of traffic without manual intervention. | While Microservices can be made to scale, they often require additional setup for auto-scaling, load balancing, and infrastructure management. |
| Serverless follows a pay-as-you-go model. You are billed for the actual compute resources used during function executions. | While Microservices can be scaled, they often require additional setup for auto-scaling, load balancing, and infrastructure management. |
| In Serverless, you deploy individual functions, each serving a specific purpose. | Microservices can have a more predictable cost model but may involve ongoing infrastructure costs even when services are not under heavy use. |
| Serverless reduces infrastructure management complexity but may introduce complexity in function orchestration and event handling. | Microservices architecture requires more upfront design and infrastructure management, making it suitable for large-scale, long-term projects. |
Conclusion
Serverless architecture has become a foundational model for building modern, event-driven applications in 2026. Its ability to scale instantly, reduce infrastructure overhead, and optimize cost makes it a strong fit for APIs, data pipelines, IoT workloads, and ML triggers.
However, successful serverless adoption requires the right observability stack. Middleware Serverless Monitoring provides end-to-end visibility into your serverless applications. It gives teams granular visibility into serverless functions, cold starts, latency patterns, and downstream dependencies so you can fix issues before they impact users.
If you’re scaling serverless workloads, make monitoring a core part of your architecture from day one.
What is meant by serverless architecture?
Serverless architecture, also known as Function as a Service (FaaS), is a cloud computing model where the cloud provider manages the infrastructure needed to run code. In a serverless architecture, developers can focus solely on writing and deploying code without worrying about the underlying server infrastructure.
What are examples of serverless architectures?
Some examples include image processing workflows, chatbots, real-time data pipelines, IoT stream processing, scheduled jobs, and API backends built using AWS Lambda, Azure Functions, or Google Cloud Functions.
Is Kubernetes a serverless architecture?
No. Kubernetes manages containers and underlying infrastructure, whereas serverless abstracts servers entirely. However, tools like Cloud Run and Fargate bridge the gap by offering serverless containers.
What is the difference between Kubernetes and serverless architecture?
Kubernetes functions as an infrastructure-level tool responsible for managing containers and infrastructure, whereas Serverless Architecture operates as an application-level abstraction for server management.
It enables developers to concentrate solely on code. The differences between the two encompass scalability, resource allocation, cost models, and complexity.
The choice between Kubernetes and Serverless Architecture depends on specific application requirements, workload, and team expertise. Some solutions even integrate both to leverage the strengths of each approach.