
The rise of advanced Large Language Models (LLMs) like GPT-4o, Lamda, and Mistral has changed the face of AI. While these models offer immense capabilities, they also introduce complexities that require careful monitoring and fine-tuning. The biggest question: how do we truly understand what’s happening inside these black box systems?
This is where LLM Observability comes in, it enables AI practitioners to gain insights into the internal workings of these models, offering tools to optimize performance, detect issues, and ensure reliability.
In this guide, we’ll explore how Middleware provides practical tools to monitor LLMs. Through metrics, traces, and real-time dashboards, Middleware offers AI developers and data scientists a detailed view of their LLM models’ performance.
Understanding LLM observability
LLM Observability refers to a more in-depth approach to monitoring large language models, where it captures not only the basic outputs but also metrics, traces, and patterns of behavior. For example, tracing allows you to see how a model processes a prompt and how much time it takes to respond, revealing latency issues or inefficiencies that traditional monitoring might miss.
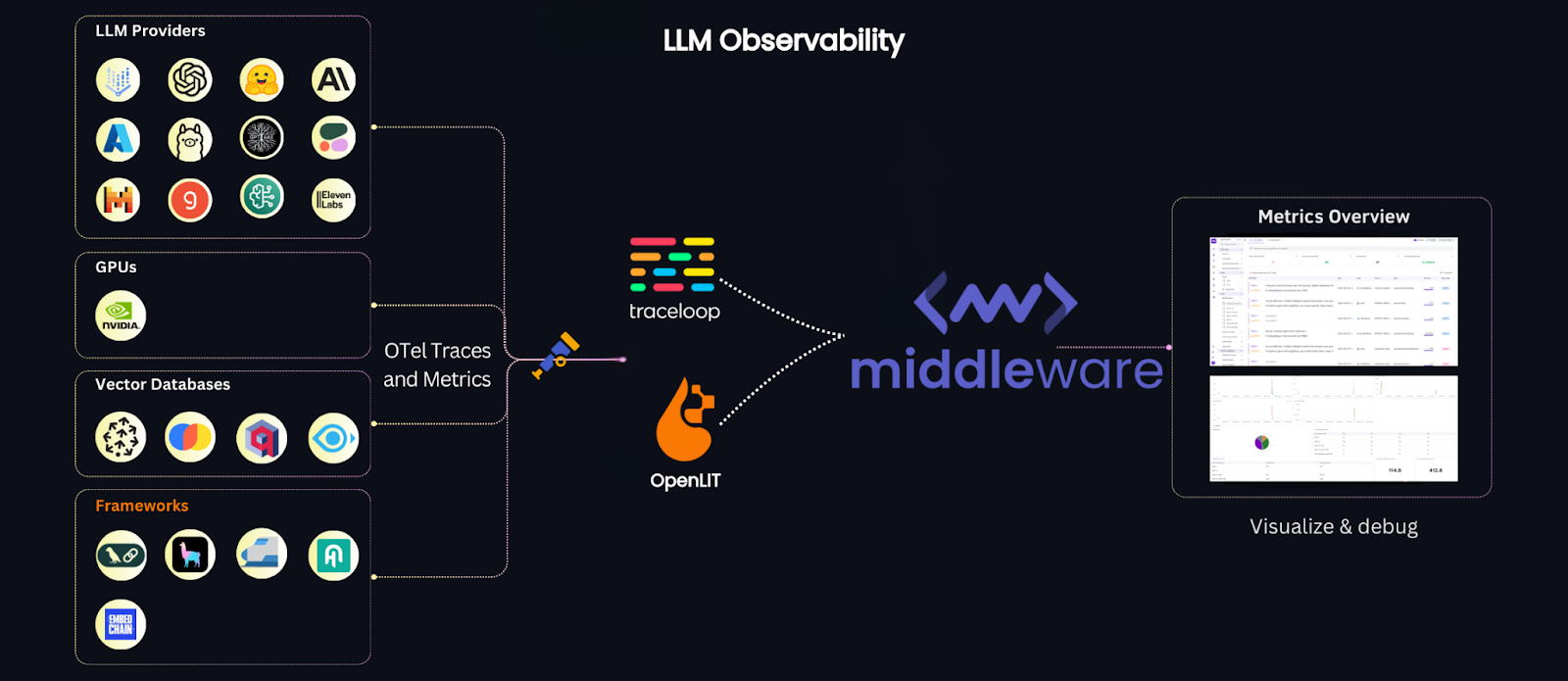
At its core, LLM Observability provides visibility into how LLMs function in real-time, offering critical insights beyond just basic monitoring and how each step of the LLM’s response generation and prompt processing happens. For instance, by capturing traces, you can observe how a model processes a prompt, whether retrieving external information or how various components interact to generate a response.
Challenges with LLMs
LLMs face unique challenges such as:
- Hallucinations: Where models generate outputs that aren’t based on facts.
- Proliferation of calls: Excessive API calls that increase operational costs.
- Proprietary data concerns: Ensuring sensitive data is managed securely within responses.
- Inaccurate or inappropriate responses: LLMs may produce responses that are incorrect, incomplete, or inappropriate, leading to confusion or harm.
- Quality of response: LLMs may produce responses that are suboptimal in terms of tone, detail, or relevance.
- Cost: LLMs can be expensive to deploy and maintain, especially when using third-party providers.
- Third-party models: LLMs accessed through third-party providers can change over time, leading to inconsistent behavior.
- Limited competitive advantage: LLMs are widely available, making it difficult to differentiate oneself from competitors.
Traditional monitoring tools often fall short when trying to capture and address these issues, underscoring the need for LLM Observability that can track and identify such issues at their source.
LLM monitoring vs. LLM observability
While traditional monitoring focuses on tracking high-level performance metrics like latency and throughput, LLM observability goes further. It provides a detailed tracing of each request-response cycle, which helps you see where bottlenecks might occur.
For instance, in an LLM with retrieval-augmented generation (RAG), observability helps you see how external knowledge retrieval impacts response accuracy and time, giving a more nuanced understanding than simple monitoring can offer.
Why is LLM Observability different from traditional observability?
Traditional observability tools often fall short with LLMs due to the complexity and non-linear nature of language models. LLMs generate responses that depend on prompts, retrievals, fine-tuning, and multiple other factors.
LLM observability requires tools that can handle the non-linear and complex nature of language models. Unlike traditional application observability, which focuses on server or application health, LLM observability has to address intricacies like:
- Prompt engineering: Understanding how different prompts influence responses.
- Fine-tuning: Ensuring the model performs well after updates or task-specific training.
- Retrieval integration: Monitoring how external data sources are combined with model outputs.
This makes LLM observability more layered and nuanced compared to standard application observability.
Five core foundations of large language model observability
To effectively implement LLM observability, you must focus on five foundational pillars. These pillars provide essential insights into various aspects of LLM performance and behavior, ensuring models function optimally across different environments.
1. Evaluation
Evaluation focuses on the continuous measurement of LLM outputs. For example, you can use automated scoring systems like BLEU or ROUGE metrics to evaluate the quality of generated text. In addition, human feedback can provide nuanced insights into model responses.
Suppose you’re using an LLM to generate customer support responses. By regularly evaluating the text quality using these metrics, you can ensure that the responses remain relevant and coherent.
Key steps:
- Gather user feedback through surveys, ratings, or comments to evaluate response quality. Alternatively, use an LLM to evaluate response quality, leveraging its ability to analyze and score outputs.
- Analyze embedding visualizations to identify patterns and problem areas. This involves using techniques like dimensionality reduction (e.g., PCA, t-SNE) to visualize high-dimensional data and identify clusters or outliers.
- Use LLMs or manual analysis to identify similarities between problematic prompts. This involves analyzing the language, structure, and content of prompts to identify common patterns or characteristics that may be contributing to poor performance.
2. Traces and spans
Tracing captures the entire request-response cycle, revealing how data flows through your LLM pipeline. By breaking down the process into spans (each representing a stage in the workflow), observability tools help pinpoint latency issues, errors, and performance bottlenecks.
If you notice delays in a content generation model, tracing could reveal that the external knowledge retrieval step is taking too long, allowing you to focus optimization efforts on that area.
Key steps:
- Repeat evaluation processes on multiple spans to narrow down problems. This involves analyzing the sequence of events, requests, and responses within a workflow to identify bottlenecks, errors, or performance issues.
- Collect relevant metadata like token usage and prompt details.
- Visualize traces to understand the flow and optimize bottlenecks.
3. Retrieval augmented generation (RAG)
RAG combines LLM-generated content with external knowledge sources. Observing how this retrieval impacts LLM outputs helps refine prompt accuracy and relevance, ensuring the LLM integrates external information effectively.
RAG systems combine LLM responses with external knowledge, such as databases or web content. Tracking how well external information integrates into LLM-generated outputs allows you to improve both the accuracy and relevance of the responses.
If an LLM retrieving articles from an external database frequently pulls irrelevant or outdated information, observability tools can track the retrieval’s quality, allowing you to refine your system to pull more relevant data.
Key steps:
- Monitor retrieved document relevance scores.
- Compare the outputs generated with and without external knowledge.
- Track how the retrieval sources affect overall model accuracy.
4. Fine-tuning
Fine-tuning LLMs for specific use cases requires vigilant observability to track critical metrics like training loss and accuracy. It’s essential to monitor how well a model is adapting to new data without suffering from performance degradation.
If you are fine-tuning a model for medical report generation, tracking performance against a benchmark dataset ensures the model maintains accuracy during the fine-tuning process.
Key steps:
- Set up logs for training metrics and model checkpoints.
- Track changes in model performance over time to ensure fine-tuning remains effective. This involves continuously evaluating the model’s performance on a held-out test set or using online evaluation metrics to detect performance drift or degradation.
- Use A/B testing to evaluate model versions in production environments.
Weigh the costs and benefits of fine-tuning before embarking on this process. This involves analyzing the potential benefits of fine-tuning, such as improved accuracy or reduced latency, against the costs, such as computational resources, expertise, and time.
5. Prompt engineering
Prompt engineering is about crafting prompts that elicit the best responses from an LLM. Observability in this area includes analyzing the effectiveness of different prompts and refining them over time to boost both accuracy and relevance.
You might test several variations of a prompt to generate product descriptions. By tracking which prompts consistently yield accurate, concise descriptions, you can refine the prompts further.
Key steps:
- Version and track different prompt variants.
- Measure performance metrics like token usage and response accuracy for each version.
- Implement A/B testing to optimize prompt structures.
Why LLMs need to be observed
LLMs introduce several complexities that require constant observation to ensure they operate effectively. Unlike traditional ML models, LLMs have complexities like hallucinations, which require constant vigilance.
Without observability, identifying and fixing anomalies, performance issues, or inaccuracies becomes difficult. For example, hallucinations, where an LLM generates factually incorrect information, can only be identified and mitigated with proper observability.
Observing metrics such as response latency or token usage can help detect potential issues before they impact end-users. A sudden spike in latency, for example, could indicate a bottleneck in the retrieval process that needs immediate attention. Without observability, these problems might go unnoticed until they significantly impact the user experience.
According to a 2024 study, around 18% of AI practitioners consider AI/ML capabilities crucial for observability solutions. These capabilities support AI-driven models by:
- Accelerating root cause analysis: Providing deeper operational insights to quickly identify underlying causes of issues.
- Aligning AI performance with business goals: Ensuring AI performance is consistently aligned with business objectives while reducing costs, improving model accuracy, and enhancing overall AI efficiency.
“A new facet of observability supports large language models (LLMs) and AI workflows, focusing on monitoring API calls, vector databases, model performance, and GPU usage. As organizations incorporate AI, observability platforms must track infrastructure and specifics of LLM performance and API cost-effectiveness, as AI token mismanagement can skyrocket expenses. Observability for AI is distinct from AI-powered observability, which integrates AI to streamline traditional monitoring and debugging. This dual approach addresses the unique demands of managing AI systems, ensuring models operate smoothly while controlling costs associated with high data processing.”
Sam Suthar, Founding Director, Middleware
How Middleware enables LLM observability
Middleware’s LLM Observability platform is designed to capture detailed metrics, traces, and alerts, providing a comprehensive view of your LLM’s performance. By integrating with existing ML pipelines, Middleware collects and analyzes data such as response times, token usage, and error rates. This integration ensures that you have actionable insights to optimize your LLM models, whether you’re using them in research, development, or production.
Middleware offers a comprehensive observability platform tailored for LLMs. It provides capabilities for monitoring metrics, traces, and creating alerts, giving comprehensive insights into the performance and behavior of LLMs. Middleware also integrates seamlessly with LLM providers like Ollama and Mistral, enabling real-time tracking through user-friendly dashboards.
With Middleware, you can capture:
- Response latency: How quickly the model responds to user queries.
- Token usage: Tracking token consumption to manage operational costs.
- Prompt effectiveness: Evaluating how well the crafted prompts generate the desired outputs.
Middleware can trace the path a user prompt takes from the initial query through the LLM’s response generation process. You can also configure alerts to notify you when a particular metric—such as token usage—reaches a critical threshold, ensuring that any deviations in performance are quickly addressed.
To integrate Middleware with your LLM, use their SDK documentation to set up real-time metrics and traces. After configuring, you can monitor everything from token usage to response times and create custom alerts, ensuring that your LLM is running smoothly.
What to track: Key signals to monitor
When implementing LLM observability, focusing on three essential signals helps to maintain clear insights and optimize performance:
Request Metadata:
- Model version: Track changes in model performance across updates.
- Temperature: Controls the creativity or randomness of outputs.
- Top_p: Defines how selective the model is in choosing its responses.
- Prompt details: Monitor the input sent to the LLM to evaluate its impact on generated responses.
Response Metadata:
- Tokens: Measure token usage to track costs and optimize efficiency.
- Cost: Ensure budgeting and expense management by monitoring resource consumption.
- Response characteristics: Analyze how the model outputs and detect potential inefficiencies.
Traces:
- Capture the sequence of events in the request-response cycle, especially in complex workflows like Retrieval Augmented Generation (RAG).
- Monitor how data flows through the system to identify bottlenecks and network delays.
These signals can be monitored using Middleware’s dashboard, which provides both real-time and historical analysis for actionable insights.
Hands-on: Setting up Middleware for LLM observability
Below is a step-by-step guide to integrating Middleware for LLM observability with OpenAI and monitoring key metrics like latency, token usage, and model behavior in real-time. The documentation provided by Middleware served as the foundation for this integration, allowing for a seamless setup from configuration to monitoring performance through their detailed dashboards.
Step 1: Access Middleware’s LLM observability documentation
To begin, the Middleware LLM Observability Documentation was referenced. This comprehensive guide outlines how to use Middleware’s observability features and offers detailed steps to integrate with LLMs, including OpenAI models such as GPT-3.
Step 2: Initialize Middleware in the LLM application
Next, Middleware was integrated into the OpenAI project. Following Middleware’s OpenLIT SDK instructions, the necessary API keys and headers were configured to connect the application with Middleware. This step establishes a connection between OpenAI models like “GPT-3.5-turbo” and Middleware’s observability platform, ensuring the collection of important performance data.
Step 3: Monitor key metrics and traces
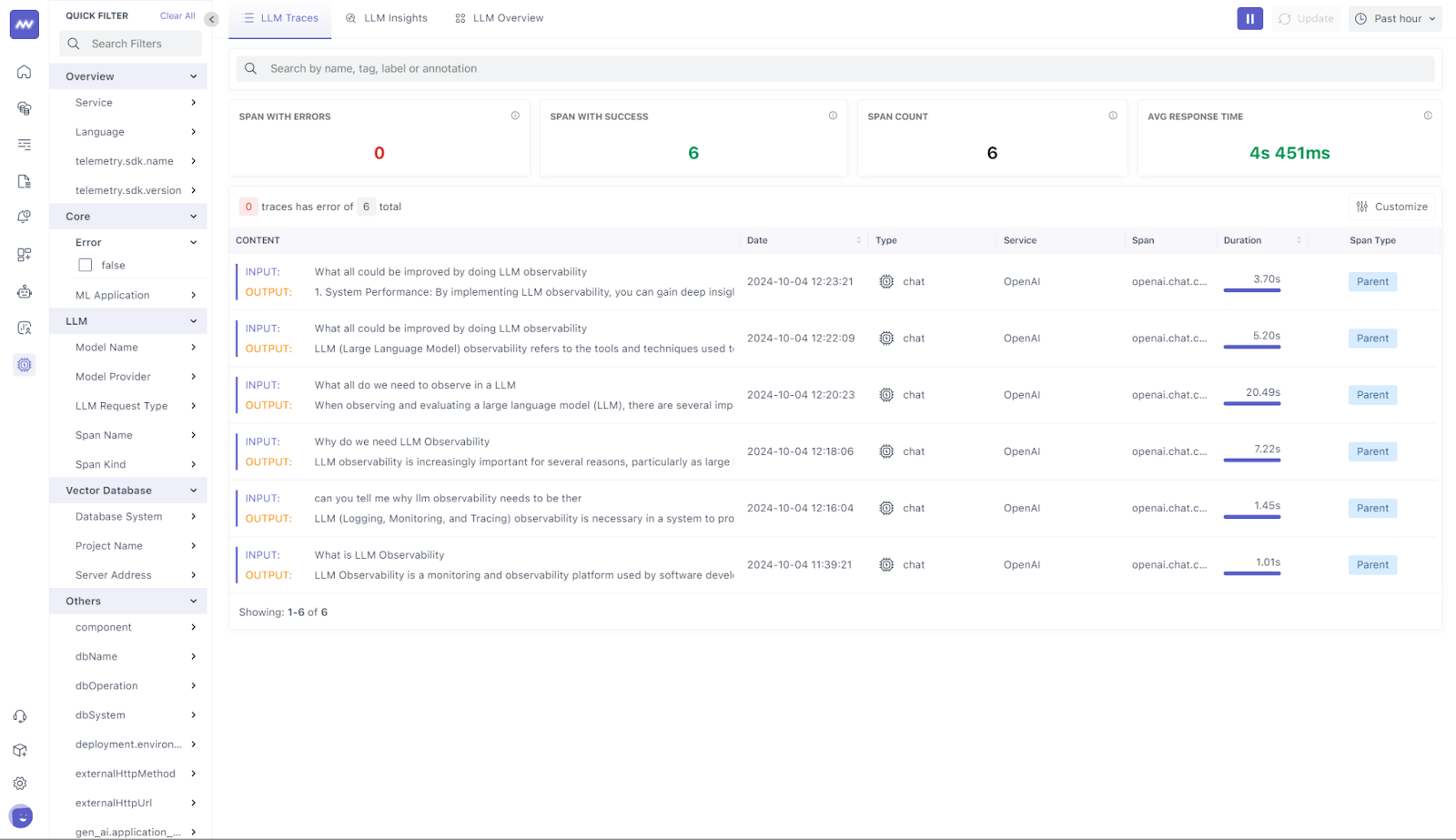
Once integrated, Middleware automatically captured essential metrics from OpenAI model interactions. The platform provided insights into critical data points like:
- Response Latency: Middleware tracked how long it took the model to generate responses, visualizing potential latency issues in real-time.
- Token Usage: Token consumption during each request was monitored, helping manage costs and optimize token efficiency.
- Request Metadata: Middleware collected details such as the model version, prompt inputs, and response lengths, offering a detailed view of how the model processed varying inputs.
Step 4: Visualizing metrics in Middleware’s dashboard
Middleware’s pre-built dashboards allowed for easy visualization of all captured data. The dashboard offered a real-time view of key metrics such as request volume, request duration, and token costs. This provided valuable insights into the performance trends of the OpenAI model and highlighted areas for potential optimization.
Traces captured the complete request-response cycle, offering deep insights into how the model handled retrieval-augmented generation (RAG). This was especially helpful for understanding how external data sources impacted the model’s outputs.
Step 5: Configuring alerts and notifications
Alerts were set up within Middleware to notify of any anomalies in key metrics, such as spikes in response latency or token usage. This functionality allowed for proactive monitoring and ensured that potential issues were detected early, minimizing any risk to performance.
Step 6: Ongoing monitoring and historical analysis
Middleware also provided historical analysis of the model’s performance, which helped track trends over time. This feature was particularly useful for identifying long-term patterns and ensuring the continuous reliability of the OpenAI model.
Step 7: Final observations
By completing the integration, Middleware provided full observability into the OpenAI model’s operations. The data and insights from metrics and traces enabled performance optimization, cost management, and ensured the model remained reliable throughout testing and production stages.
Conclusion
In a nutshell, Middleware’s LLM Observability provides real-time monitoring, troubleshooting, and optimization for LLM-powered applications. This enables organizations to proactively address performance issues, detect biases, and improve decision-making.
The platform also leverages AI and ML to dynamically analyze and transform telemetry data, reducing redundancy and optimizing costs through its advanced pipeline capabilities for logs, metrics, traces, and real user monitoring (RUM).
This way, it empowers organizations to monitor model performance with granular metrics, optimize resource usage, and manage costs effectively, all while delivering real-time alerts that drive proactive decision-making. Ultimately, Middleware promises to deliver observability powered by AI and designed for AI.



