
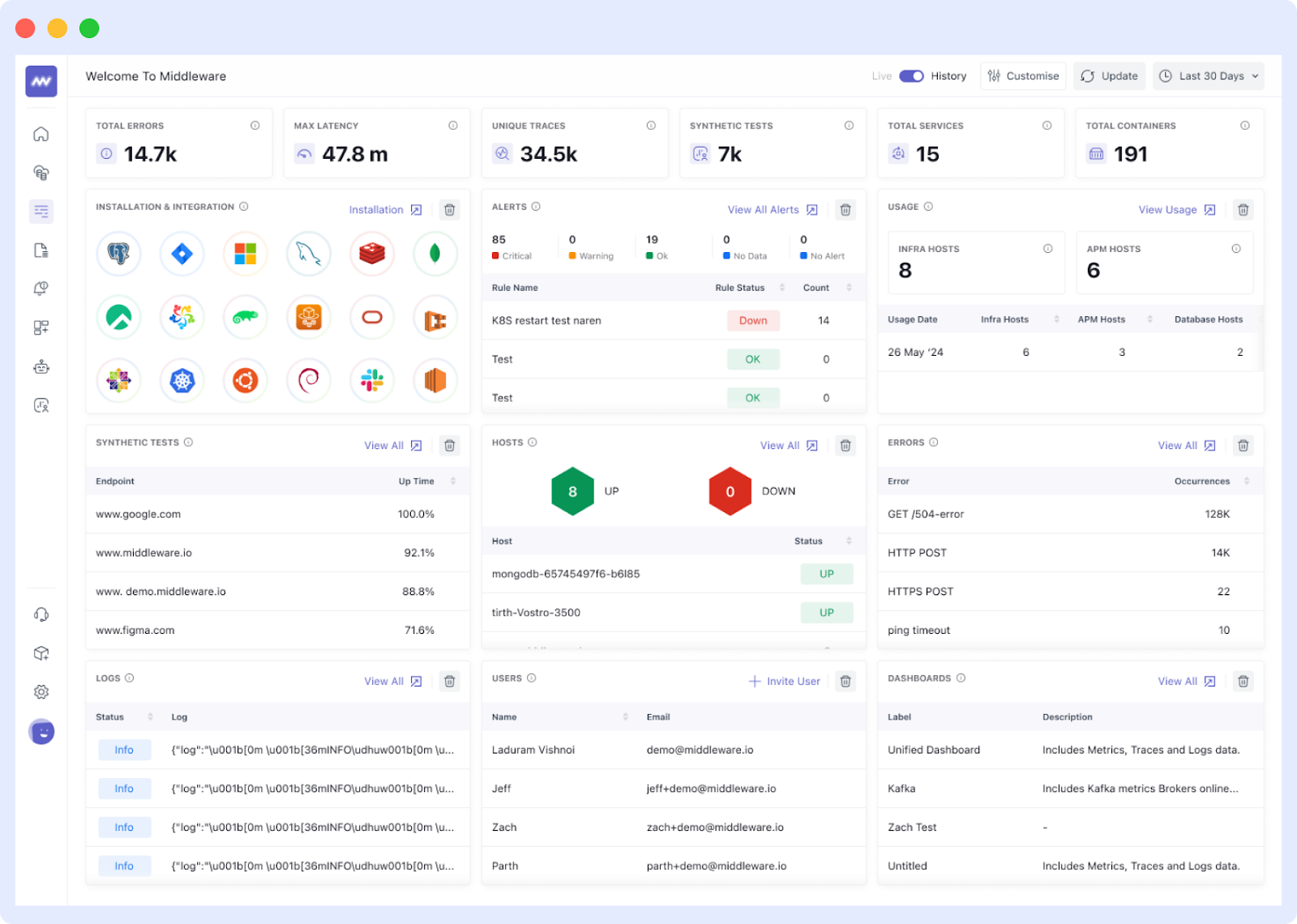
During the busy holiday season, travel platforms face immense pressure to perform flawlessly under heavy user demand. A real-world example is the Irish Rail website outage on November 22, 2024, which highlighted the critical need for reducing downtime as countless travelers were left unable to book tickets or check schedules. Passengers in Dublin and Louth were particularly affected, leading to frustration, delays, and disrupted holiday plans.
The incident highlights a major challenge: managing complex, interconnected systems during peak times. From real-time inventory synchronization to handling high transaction volumes, travel platforms must navigate intricate microservice architectures. Diagnosing and resolving such issues quickly is important to prevent customer dissatisfaction and revenue loss.
In this article, we explore the role of Middleware’s observability platform in reducing downtime, ensuring consistent user experiences, and enabling proactive management during high-demand periods, such as the holiday season.
Understanding observability in travel platform infrastructure
Travel platforms depend on interconnected systems to handle bookings, payments, and notifications. Observability provides insights into these interactions, enabling teams to quickly identify and resolve issues before they disrupt operations.
Observability helps you to quickly identify and resolve issues before they disrupt operations
What observability means
Observability goes beyond traditional monitoring by offering deeper visibility into system behavior. While monitoring highlights problems, observability explains why they occur by analyzing logs, metrics, and traces. This comprehensive view enables teams to act quickly and effectively.
Importance for travel platforms
Travel platforms require real-time updates across services—availability checks, payment processing, and notification systems—all of which must function without delays. Observability ensures these services communicate efficiently, reducing latency and errors.
Practical example
Consider the booking and payment services of a travel platform. If customers experience a delay in payment confirmations, observability can reveal whether the issue lies in the payment gateway’s API latency or a queue backlog in the booking system. By pinpointing the source, teams can resolve the issue faster, reducing customer impact.
Editor’s Choice: Top 12 API Monitoring Tools to Try
Key challenges observability solves for travel and booking platforms
High-demand periods expose vulnerabilities in travel platforms. Observability addresses challenges like managing complex dependencies, reducing resolution times, and improving root cause analysis to maintain efficient operations.
Managing complex dependencies
Travel platforms rely on interconnected services—search, booking, payments, notifications—that must operate cohesively. Observability maps these dependencies, helping teams identify and address disruptions quickly.
Reducing detection and resolution time
Observability tools help reduce Mean Time to Detect (MTTD) and Mean Time to Resolve (MTTR), enabling faster fixes. For example, if a flight search feature slows down during peak hours, traces can pinpoint whether the issue is in the search API, database, or an external API dependency.
Improving root cause analysis
During downtime, identifying the root cause is important to prevent recurrence. Observability allows teams to trace issues back to their origins, such as a misconfigured load balancer or an overloaded microservice.
Middleware insights: Enhancing observability
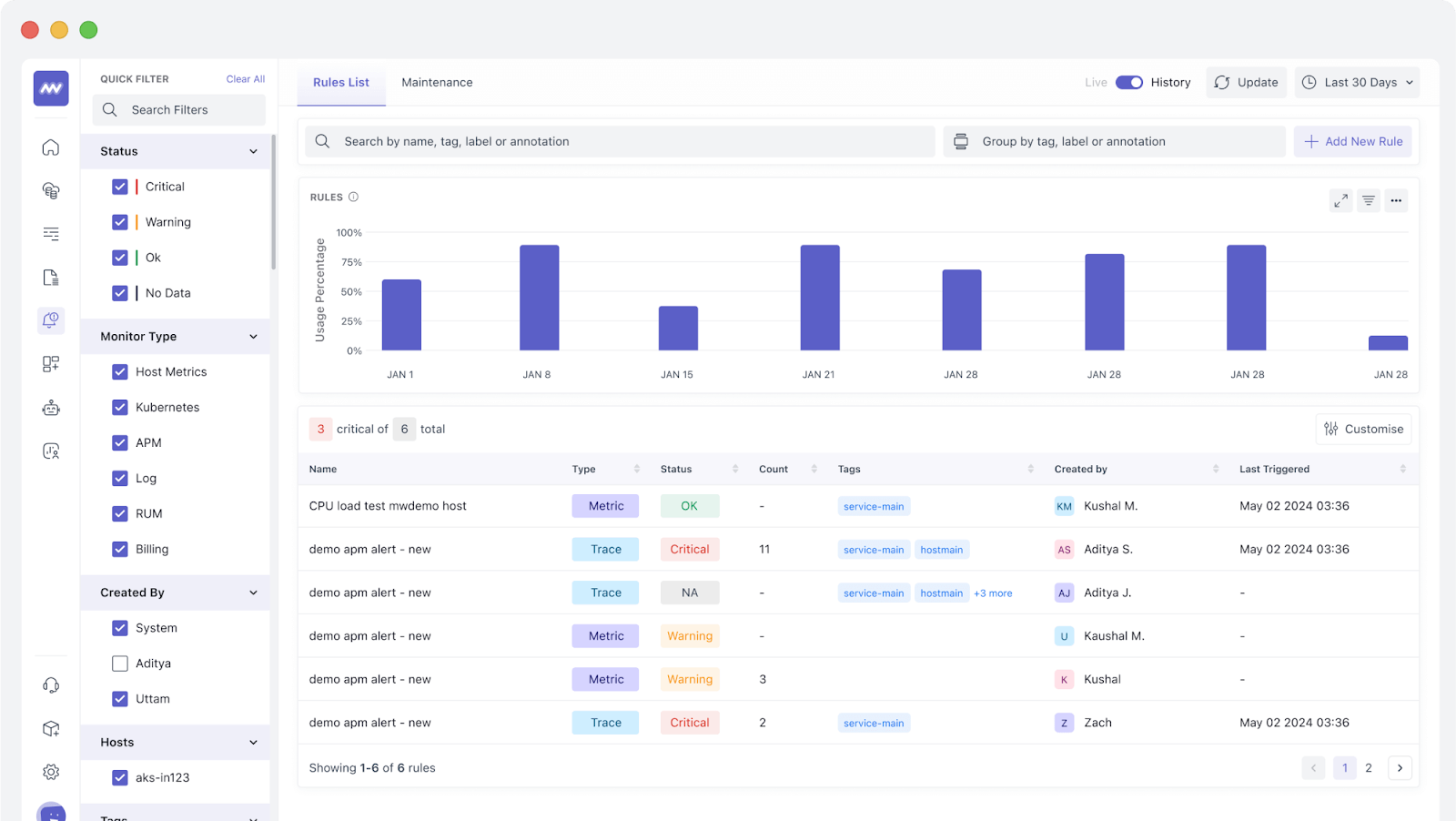
At the heart of observability lies actionable insights that enable teams to understand and resolve issues effectively. Middleware’s observability platform integrates the three pillars of observability, logs, metrics, and traces, into a unified solution, offering unparalleled visibility across complex infrastructures.
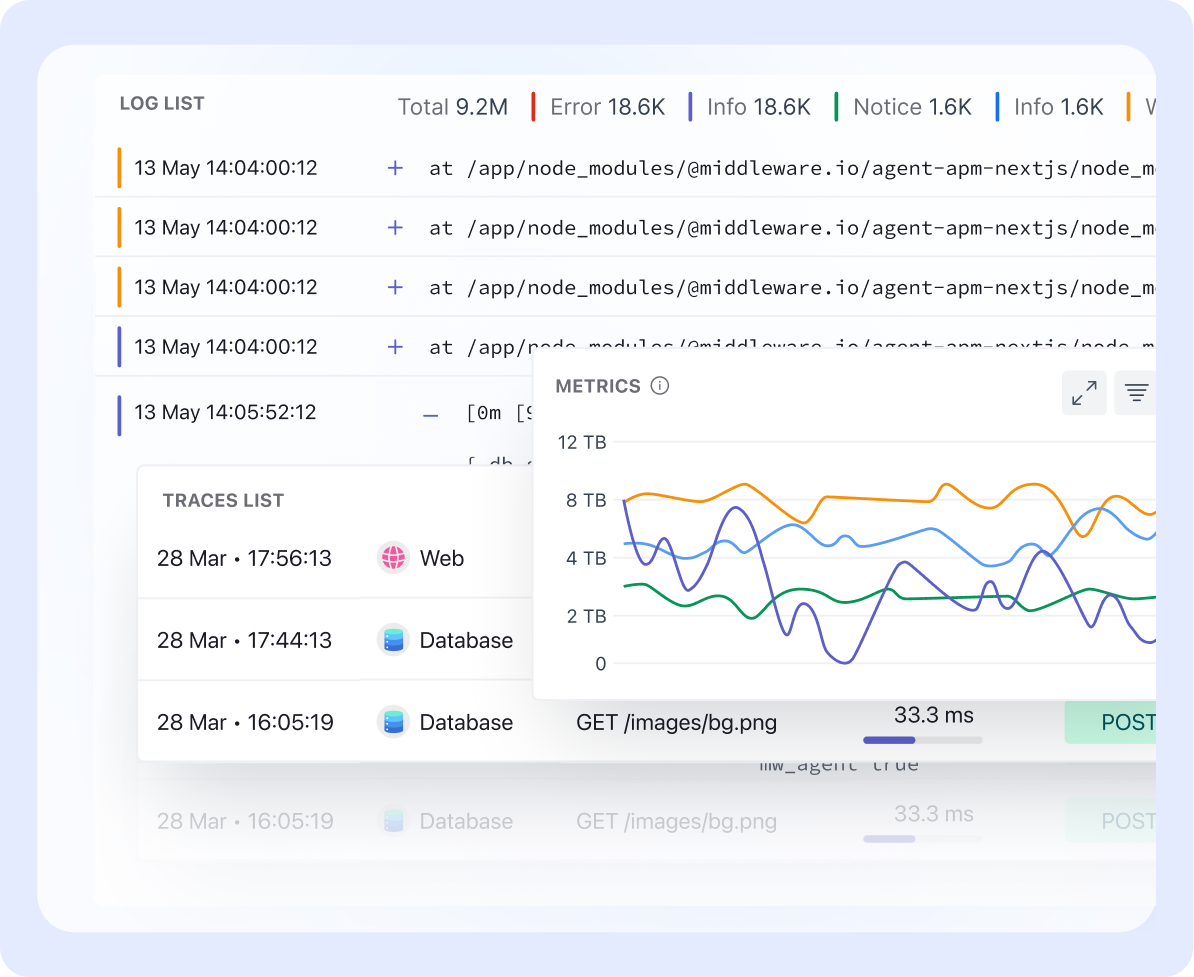
Middleware Logs
Middleware captures detailed logs across all services, providing a chronological account of events. These logs help pinpoint anomalies, such as failed API calls or unauthorized access attempts, enabling teams to take immediate corrective action.
Middleware Metrics
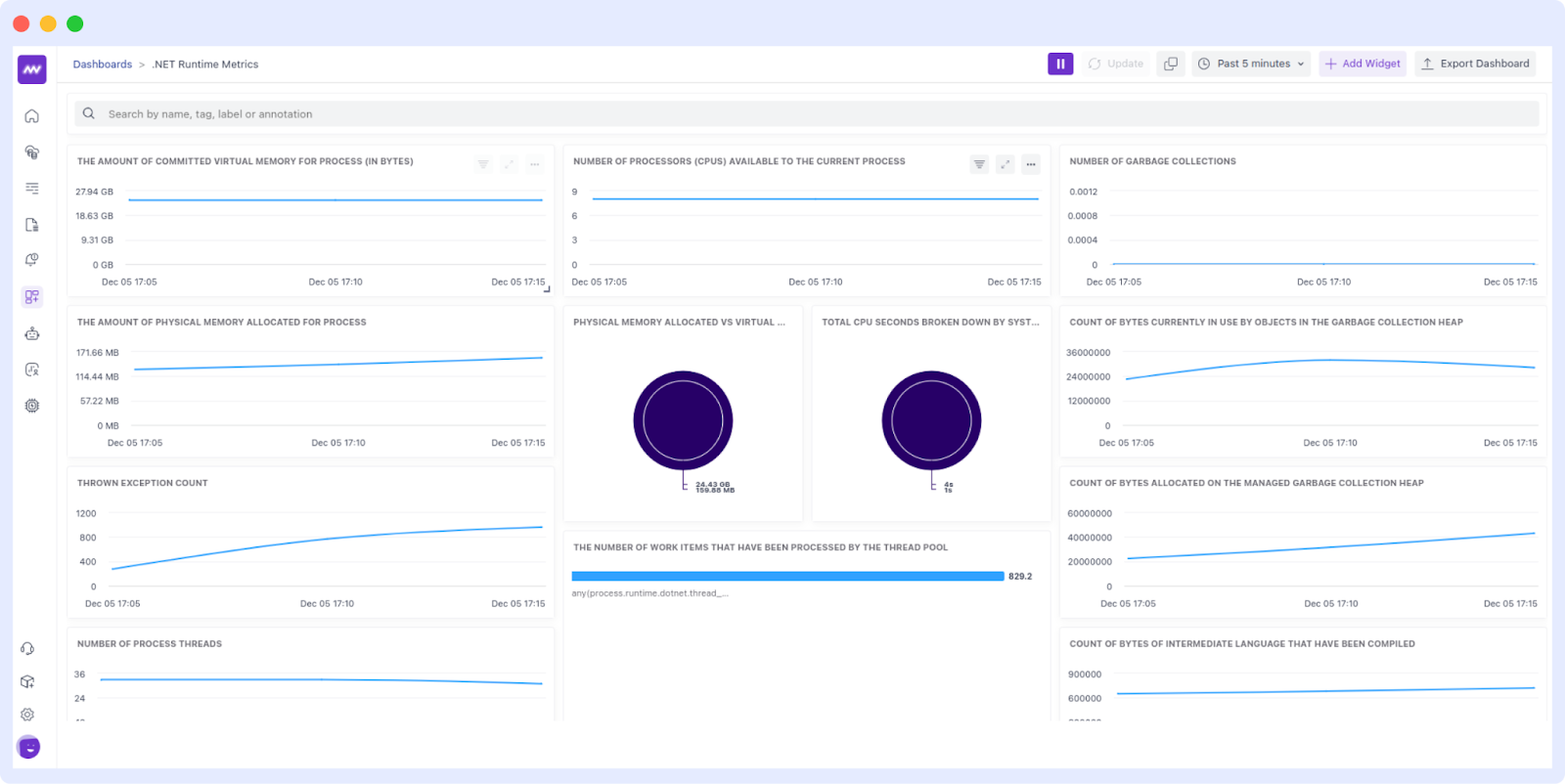
With Middleware’s customizable dashboards, teams can monitor key performance metrics like response times, error rates, and resource utilization in real-time. These metrics help identify patterns and predict potential failures before they occur.
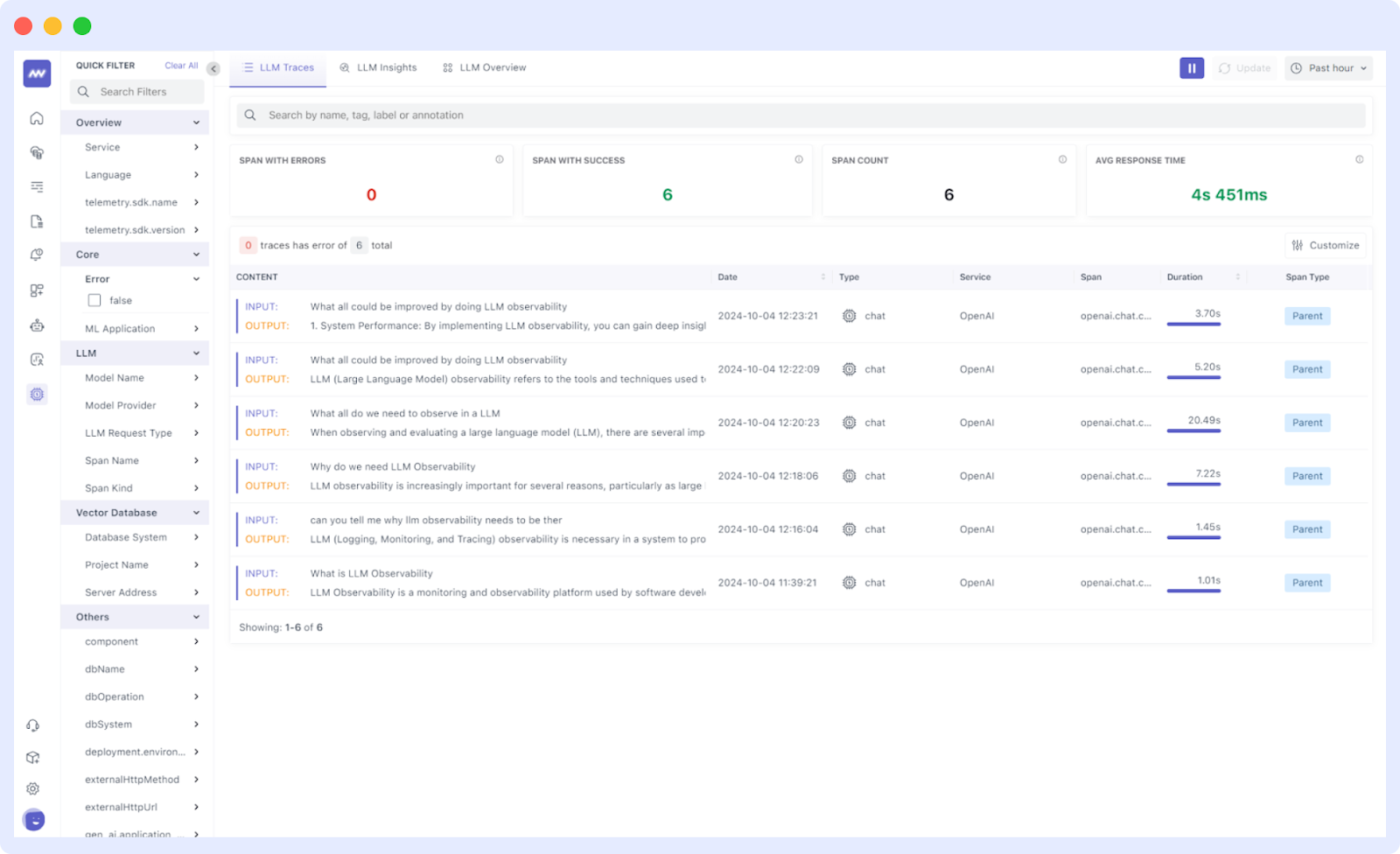
Middleware Traces
Tracing is crucial for understanding how requests flow through interconnected services. Middleware’s tracing tools map the entire lifecycle of a request, from booking to payment processing, highlighting bottlenecks and dependencies.
Building a feedback loop and continuous improvement with Observability
Effective observability goes beyond identifying and resolving immediate issues. It lays the groundwork for continuous improvement by creating a feedback loop that turns every incident into a learning opportunity. This proactive approach not only improves system resilience but also equips teams with the tools to prevent similar issues in the future.
Proactive issue detection for high-demand events
Observability tools like Middleware are invaluable for anticipating challenges during high-demand periods, such as holiday travel or seasonal sales. By analyzing historical traffic patterns, teams can identify trends and forecast potential bottlenecks.
For example:
- Traffic analysis: Historical data might reveal that user traffic doubles during a holiday week. Based on this insight, observability tools like Middleware can recommend scaling strategies to ensure the infrastructure can handle the load.
- Load testing: Teams can simulate anticipated traffic spikes using observability metrics to assess system performance under stress. This enables them to proactively address vulnerabilities before they affect users.
- Resource allocation: By understanding how previous traffic patterns impacted specific services (e.g., payment gateways or inventory databases), teams can pre-scale resources like servers, database connections, or API limits to maintain smooth operations during peak demand.
By taking these proactive steps, you can minimize the risk of downtime, ensuring that their platform is prepared for both expected and unexpected surges in user activity.
Editor’s Choice: How Hotplate elevated customer experience during high-traffic events
Incident analysis and feedback loop
Every system disruption or performance issue presents a chance to learn and improve. Middleware collects detailed data during incidents, which can be analyzed post-event to refine processes and improve platform resilience. Key components of this feedback loop include:
- Incident review: After an outage or performance degradation, teams can use Middleware to analyze telemetry data (e.g., logs, metrics, and traces) to understand what triggered the issue. For example, observability might reveal that a database query became a bottleneck during a surge.
- Process refinement: Insights from the analysis can guide teams in improving their systems. In the case of the database query bottleneck, teams might:
- Optimize the query logic to reduce execution time.
- Implement caching for frequently accessed data.
- Scale the database infrastructure to better handle peak loads.
- Implementing safeguards: Observability also helps teams identify preventative measures. Such as:
- Rate limiting: Setting limits on API requests to prevent overload during traffic spikes.
- Alert tuning: Adjusting alert thresholds to detect anomalies earlier and minimize false positives.
- Improved automation: Automating failover mechanisms to reroute traffic in case of service disruptions.
- Continuous monitoring and adaptation: As systems and user behavior evolve, observability ensures that teams can continuously adapt. Observability tools monitor the effectiveness of implemented changes, providing real-time feedback on whether they have resolved the root cause or need further adjustments.
Benefits of the Feedback Loop
- Reducing downtime: Using Middleware, teams can analyze past incidents and prevent recurring issues while improving response times.
- Optimizing performance: Proactive scaling and improved configurations build platform reliability, even during high-demand events.
- Improving collaboration: Insights from observability foster collaboration across teams (e.g., development, operations, and database admins), ensuring everyone is aligned on how to improve system performance.
Incorporating observability into the feedback loop creates a virtuous cycle of learning, refinement, and adaptation. This approach ensures that systems remain resilient, efficient, and capable of meeting user expectations, even under the most demanding circumstances.
Strengthening travel platform resilience and compliance with observability
Travel platforms must balance performance with regulatory compliance. Observability tools ensure data security, monitor stability and help meet compliance requirements.
Regulatory and security integration
Travel platforms handle sensitive customer data, making compliance with regulations like GDPR or PCI DSS necessary. Observability tracks access logs and identifies anomalies, ensuring data security. It can flag unusual API usage patterns, preventing potential breaches.
Security and stability monitoring
Real-time observability detects vulnerabilities and unusual activity, such as spikes in failed login attempts. Addressing these issues promptly protects both customer data and platform stability.
Observability vs. traditional monitoring in flight booking systems
Traditional monitoring identifies symptoms, but observability reveals the causes. This approach helps travel platforms prevent recurring issues and maintain stability.
Key differences
Traditional monitoring reacts to incidents, while observability identifies anomalies proactively. For example, monitoring might alert you to a high error rate in the payment system, but observability reveals that the issue is due to a surge in retry requests caused by a downstream API timeout.
Limitations of monitoring alone
Monitoring tools often miss subtle performance degradations, such as slow response times in interconnected services. Observability provides deeper insights, uncovering hidden issues that could disrupt bookings.
5 key strategies for building effective observability in travel platforms
To get the most from observability, align with business goals, prioritize scalable tools, and focus on ease of use to support efficient travel platform operations.
- Align with business goals: Focus on metrics that impact customer satisfaction, such as uptime and response times.
- Prioritize scalability: Use tools capable of handling high volumes of data without slowing down the system.
- Ease of use: Ensure dashboards and alerts are intuitive so teams can act quickly.
- Smooth integration: Embed observability into workflows like incident response and customer support.
- Cost-effectiveness: Evaluate observability solutions based on ROI to balance costs and benefits effectively.
Editor’s Choice: 10 Monitoring Best Practices Every Developer Should Know
Major hurdles in implementing observability for high-traffic platforms
Poor observability practices, like data overload or inconsistent formats, can undermine efficiency. Avoid these pitfalls to maximize observability’s value.
Data overload
Overwhelming teams with excessive metrics and logs can obscure meaningful insights. Prioritize actionable data, such as error rates and latency trends.
Maintaining data quality
Consistent data can lead to more informed decisions. Regular audits and clean pipelines ensure accuracy.
Avoiding tool overlap
Using too many observability tools can create operational confusion. Standardize on a core observability stack for clarity and efficiency.
Conclusion
Observability is necessary for travel platforms aiming to maintain uptime and deliver smooth customer experiences during high-demand periods. Middleware’s observability platform provides the insights necessary to reduce downtime, resolve issues faster, and build resilient infrastructures.
Looking ahead, trends like AI-driven observability promise even greater predictive capabilities, helping travel platforms prepare for the future while minimizing disruption and ensuring customer trust.
What is observability?
Observability is the ability to understand a system’s internal state based on external outputs, such as logs, metrics, and traces. It allows teams to monitor and analyze system performance, identify anomalies, and resolve issues efficiently.
What is observability in DevOps?
In DevOps, observability enables teams to monitor and analyze the health and performance of applications and infrastructure. It supports continuous delivery by providing insights into deployments, detecting errors early, and ensuring system reliability.
What is the goal of observability?
The primary goal of observability is to provide actionable insights into system behavior. It helps teams detect anomalies, optimize performance, and ensure system reliability by enabling proactive issue detection and resolution.
How does observability help with root cause analysis and faster issue resolution?
Observability correlates data from logs, metrics, and traces to provide a comprehensive view of system behavior. This unified approach helps teams pinpoint the root cause of issues quickly, reducing Mean Time to Detect (MTTD) and Mean Time to Resolution (MTTR).
What are the best practices for implementing observability in high-demand systems?
Implementing observability in high-demand systems starts by focusing on critical services that have the most significant impact during peak times, expanding coverage gradually.
Utilize distributed tracing to monitor interactions between microservices, enabling better visibility into dependencies and bottlenecks.
Set up real-time alerts and dashboards for actionable insights, ensuring quick responses to issues.
Standardize data formats across logs, metrics, and traces to maintain consistency and improve analysis.
Continuously refine observability configurations based on evolving system requirements and learnings from past incidents to build a more resilient and adaptable platform.



