Although still in its infancy, Web3 is quickly dominating the marketplace:
- In H1 of 2022, Web3 companies raised more than $1.8 billion
- 46% of finance apps are based on the Web3 technology
- There were 18,416 monthly active Web3 developers in December 2021
If you don’t want to be blindsided by the oncoming transformation, it’s important to start considering how your processes will adapt to Web3 architecture. Specifically: how will Web3 observability differ from previous iterations?
What is Web3 architecture?
Web3 is (not surprisingly) the third iteration of how internet applications are built and run. In short, this three-phase can be described as follows:
- Web 1.0 is the “read-only Web,” where developers could build webpages for people to visit and view, but there was no way for users to interact with them
- Web 2.0 is the “social Web,” where users can add and edit website content, enabling everything from social media to cloud applications.
- Web 3.0 (or Web3) is the “distributed Web” or the “semantic Web,” which includes both machine readability as well as the rise of blockchain-based application architecture.
While there are many differences between Web 2.0 and Web3, perhaps the most important for observability is that of distribution. With assets spread across the cloud and connected only through blockchain, it will require a complete transformation of how applications are built and monitored.
Web 2.0 vs. Web3 applications
At their core, Web 2.0 applications require three central components:
- Data storage, which in turn requires a constantly updated database
- Backend code (e.g. Java or Python) that defines the application’s business logic
- Frontend code (e.g. JavaScript, HTML, and CSS) that defines the application’s UI logic
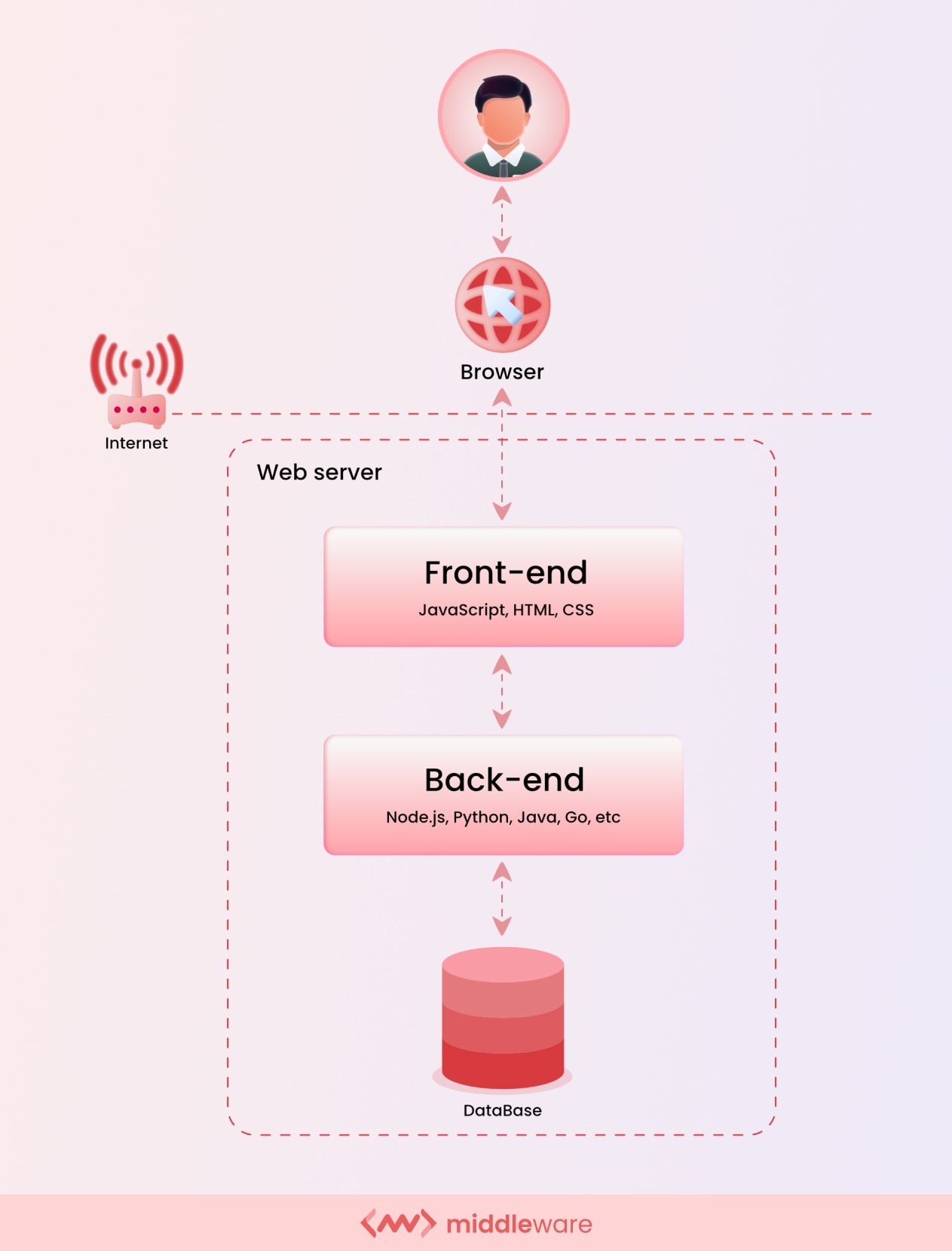
The primary difference between Web 2.0 architecture and Web3 architecture is that Web3 eliminates the middleman. There’s no longer a need for a database to store information or a centralized server where the backend logic resides.
Instead, Web3 developers leverage blockchain to build apps on a decentralized state machine maintained by anonymous nodes on the internet. Blockchains are state machines that have an instantiated genesis state, and very strict rules define a state transition.
In terms of control, no single entity controls the decentralized state machine—everyone on the network collectively maintains it.
So instead of operating a backend server, Web3 developers write smart contracts that define the logic of applications, then deploy them onto the decentralized state machine. This allows any person who wants to build a blockchain application to deploy code on this shared state machine. The front end, generally speaking, remains the same.
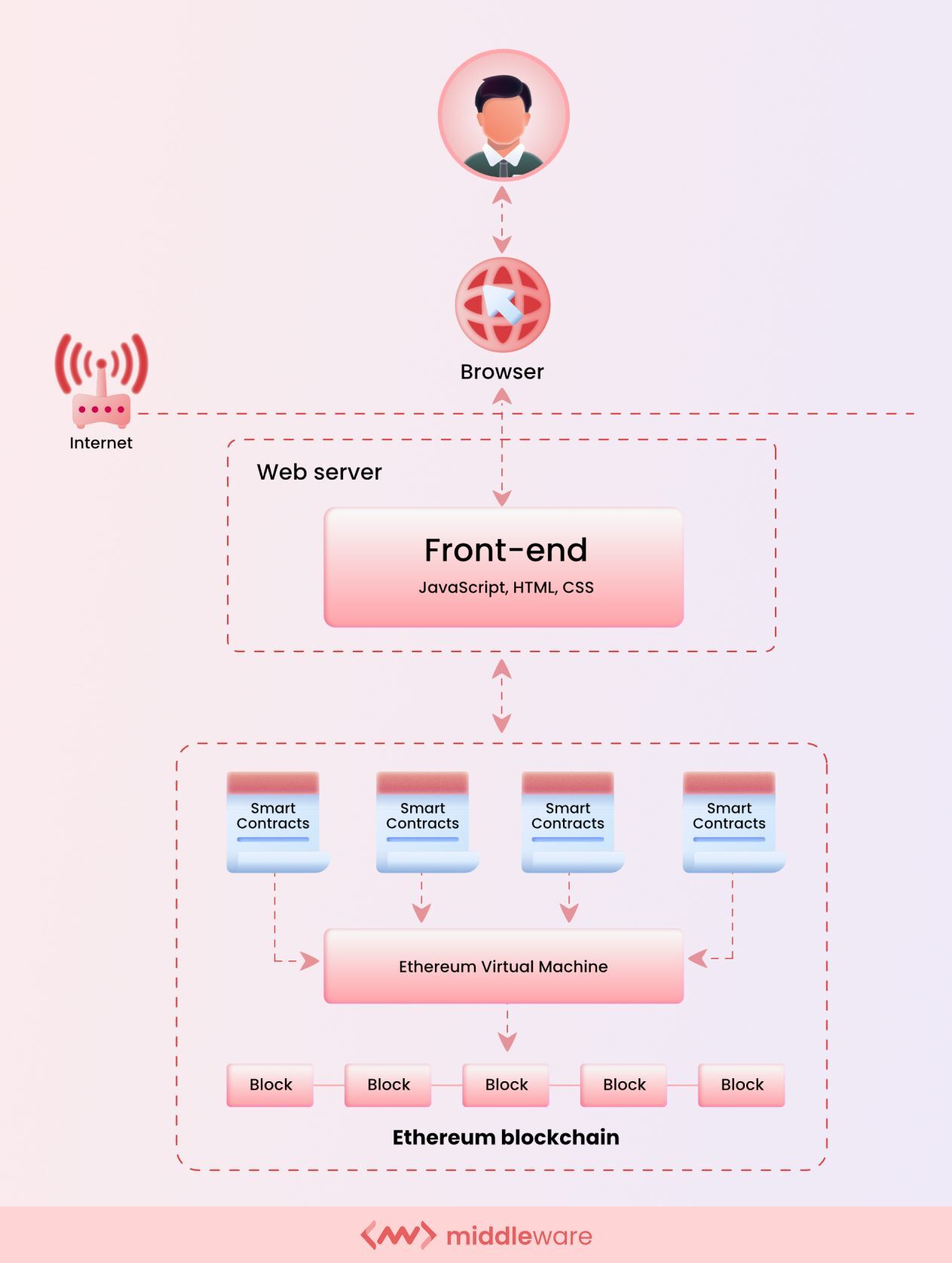
Web3 application architecture components
In the previous section, we described several components that go into Web3 application architecture. Now let’s take a closer look at each of them.
Blockchain
There are multiple types of blockchains, but each of them has fundamentally the same structure. Blockchains are globally accessible, deterministic state machines maintained by a peer-to-peer (P2P) network of nodes. State changes on the blockchain are governed by rules of consensus that peers in the network follow.
Data written into the blockchain can only be written, not updated. This is because data is not maintained centrally but collectively by everyone in the network.
Smart contracts
Smart contracts define the logic of your applications and deploy them onto the decentralized state machine. In this paradigm, web servers and traditional databases are no longer needed since everything is done on or around the blockchain. Smart contracts are written in high-level languages, such as Solidity or Vyper.
Virtual machine
The central component of Web3 architecture is the virtual machine. This system executes the logic defined in smart contracts and processes the state changes that happen. For this work, developers must compile high-level languages into bytecode, which the virtual machine then executes.
P2P database
Because blockchain is slow and expensive, P2P databases form an essential component of the system. P2P databases enable developers to access data off-chain, which reduces access points and, by extension, costs. This architecture eliminates centralized database servers and local storage.
Authentication
One of the unique advantages of blockchain is that in order to access a smart contract, users must provide authentication at every step. This happens through private keys that are unique to each user. As such, the very structure of authentication and security changes when adopting a Web3 infrastructure.
In Web3, applications don’t hold user data but wallets that leverage cryptographic signatures to prove ownership of specific blockchain addresses. If a user loses their private key to the wallet address, no one can recover it for them.
Front end
Finally, there’s the part of the application that the user will engage with themselves. Generally speaking, the front-end technologies for Web3 are the same as Web 2.0. The only difference is that developers need to reimagine the UX of the application to accommodate authentication and processing in the blockchain.
Complications of Web3 applications
Although Web3 applications are filled with potential, they’re still a new technology. As such, there are complications and drawbacks that developers need to know.
Scalability
Decentralized applications (or dapps) have difficulty scaling up because the cost of running them on a particular blockchain server increases with usage. Each transaction requires a fee (called “gas”), which is subject to extreme price volatility.
To solve this problem, developers can adopt decentralized, off-chain storage solutions like Interplanetary File Systems (IPFS) or Swarm, which leverage P2P network architecture.
User experience
Dapps generally have a poor user experience compared to traditional web applications. The primary reason: their complex architecture, technical limitations, and environmental impact make them slow, difficult to use, and not very reliable. This is one reason why there are no mainstream dapps to speak of, even in 2022. Most current dapps are related to money—namely cryptocurrency.
Data collection & storage
The thing that sets software companies apart is not their features and functionality, UI/UX, or business logic but the data they’ve aggregated. Web3 disrupts this reality, making every application composable by sharing and consuming data between applications.
Observability
In Web 2.0, observability has become a norm. In Web3, however, the transformation of systems architecture makes this observability much more complicated. While some centralized aspects of Web3 can rely on Web 2.0 observability tools and tactics, there are still significant blind spots that developers need to overcome if they’re going to adopt a Web3 architecture.
What is Web3 observability, and how does it work?
No complex system is ever fully healthy. If this was true for Web 2.0, it’s even more true for Web3. Highly decentralized systems are inherently unpredictable. Without observability, developers and engineers are stuck making assumptions about system behavior and basing their decisions on those assumptions.
In Web 2.0, observability depends on three fundamental components: logs, metrics, and traces. By processing these data into a usable format, observability platforms surface the most important insights, enabling developers and engineers to quickly address errors at the root cause.
So how do developers maintain their current observability expectations in a distributed Web3 environment? Here’s how those three observability components function differently in Web3.
Web3 logs
A log is an immutable, timestamp record of discrete events over time. Its primary function is to provide insights into application performance over time, particularly when evaluated within its proper context. By collecting logs, engineers can catch issues in real-time.
The primary difference between logging in to Web 2.0 and Web3 is the volume of logs. Every bit of data that a smart contract incurs will require more “gas.” Observability platforms need to become smarter in sorting through the most relevant data, leaving out events that aren’t critical for assessing system performance.
Get real-time metrics, traces and logs in one place with Middleware observability platform.
Most modern log management systems collect logs and automatically aggregate, index, and analyze them to surface the most important insights. This capability will become even more important as Web3 increases the volume of logs that observability platforms compile.
Web3 metrics
A metric is the numerical representation of data measured over time. Metrics in observability detect system anomalies, which can clue engineers into problems as they arise. Metrics are stored in a time series database and contain a name, label, numeric value, and timestamp in milliseconds.
Web3 metrics aren’t that different from their Web 2.0 counterparts. Blockchain data is public data, and each entry in the distributed ledger already has a timestamp. All developers and engineers have to do are set up the data pipeline and warehouse.
One key difference, however, is that Web3 enables the collection of additional metrics related to specifications of transactions:
- Event logs
- Gas burn
- Time elapsed until confirmation
- Input/output specifics
Web3 traces
While logs and metrics are fairly straightforward in Web3, tracing is different. To implement tracing, every component in the path of a request needs to propagate that tracking information. Because of the decentralized nature of blockchain, this is more difficult than in a centralized cloud platform.
It is important here to consider the two most common types of tracing methods:
- Stack tracing consists of logs and metadata issued by an application runtime, containing all invocations from the start of a threat until an exception
- Distributed tracing is the observation of the end-to-end path of causally related distributed events flowing as a request through a distributed system, allowing developers to see which services are involved in the request.
Stack tracing is the only method that works for Web3, as there is no way to follow a transaction from the UI to persistence layers without further context. Many developers are now employing a hybrid approach, using distributed tracing for Web 2.0 components and adapting stack tracing for Web3.
However, overall there are severe limitations to Web3 tracing. Overcoming this challenge needs to be a priority for developers and engineers in the Web3 space if these types of applications are ever going to become mainstream.
Why existing web2 tools don’t work in web3
There are a few key reasons why existing web2 tools don’t work in web3.
First, web2 is built on a centralized architecture, whereas web3 is built on a decentralized architecture. This means that web2 tools rely on central servers, while web3 tools do not.
Second, web2 tools are typically designed to be used by humans, while web3 tools are designed to be used by machines. This means that web2 tools are not well-suited for interacting with the decentralized data and applications of the web3 world.
Finally, web2 tools are often closed and proprietary, while web3 tools are open and decentralized. This means that web2 tools cannot take advantage of the many benefits of the web3 world, such as the ability to connect to and interact with a variety of different decentralized networks.
Therefore the best way is to build your applications on web3 based architecture Alchemy instead of hosting on AWS, and then, you can easily monitor your smart contracts and decentralized applications.
When do you need to think about web3 observability
When you’re either already running web2 applications, partially moving to or creating standalone web3 applications, then you should consider web3 observability at different stages of your company’s development.
We at Middleware provide full-stack observability for web2 and web3 applications. So, if you’re already using tools A, B, and C, then you should probably think about using Middleware. Motivate your readers to think about where they are in their journey and if they should think about web3 observability.
Achieve complete observability in your existing infrastructure with Middleware.
The benefits of Web3 observability
The benefits of Web3 observability are similar to the benefits of Web2, with one notable difference: Web3 observability is uniquely set up to function in a decentralized environment. As such, some of the benefits are slightly different depending on context:
- Because decentralized systems have no single source of truth, Web3 observability provides much-needed transparency
- Engineers can document the production environment and get the information needed to improve it without spending hours accessing various blocks and nodes.
- Develop a comprehensive understanding of the distributed environments
- Detect issues as they arise, and address the problem in real-time
At the end of the day, Web3 engineers are dealing with a complex array of systems with multiple points of failure. While decentralization does help mitigate overall risk, it is important to understand where points of failure occur and have a comprehensive idea of overall system health. Without it, they’ll be flying blind.
Final thoughts on Web3 observability
Like the architecture itself, Web3 observability is in its nascent stage. In order for companies to rely on these new technologies to provide the foundation for their business, they’ll have to become more mature.
Yet perfect should never be the enemy of good. By leveraging the available technologies to improve observability in Web3 environments, engineers can create more reliable, efficient, and innovative applications and take advantage of decentralization and its benefits.
Learn more about how Middleware can provide observability into your entire tech stack here.



