![What is Service Discovery? Complete guide [2026 Edition]](https://middleware.io/wp-content/uploads/2021/09/what-is-service-discovery-copy.jpeg)
Microservice architecture is extremely useful for developers while they create large and complex applications with multiple services. Microservices help to manage these applications by working with them as a cluster of small services that combine to form a major functionality.
This cloud-native architectural approach has extensive usages for the developer community and lets them control many loosely attached and individually deployable components inside an application.
A service-oriented architectural style becomes important when the services are complex, fine-grained, and encompass small but crucial functionalities. It has lightweight protocols that suit long-running applications requiring management and resource utilization. Microservices ensure that the application remains scalable, error-free, and easy to maintain.
However, when you are working with so many small services combined together, it becomes crucial for each service to locate and communicate with one another to get a job done. This is where service discovery in microservices comes into play.
What is Service Discovery?
Service discovery is the technology to automatically detect services and devices on a computer network. It is how applications and microservices locate different components on a network. A service discovery protocol is a network protocol that implements this technology and reduces manual configuration tasks on the part of both the administrators and the users.
You can implement service discovery on both a central server and client-server. It simply requires a common language that allows the software to make use of one another’s services without requiring any additional intervention on the user’s part.
Why do you need service discovery?
When you are working on a microservices application, you have to deal with service instances that have dynamic locations. These instances might also need to be changed at runtime, based on factors such as autoscaling, service upgrades, and failures. In such a scenario, the services dependent on these instances must be aware.
Suppose you are working on a code that invokes a service with a REST API. The code needs the IP address and port of the service instance to make a request. Now, if your application runs on hardware, these locations remain static and do not need to be searched for every time.
However, in a microservice architecture, the number of instances will vary and they will not have their locations in a configuration file. Thus, it is difficult to know the number of services at one point in time. You need service discovery in microservices to locate service instances in dynamically assigned network locations in a cloud-based microservices location.
It helps all instances to adapt to the load and distribute it accordingly. Service discovery has three components.
- A service provider; that provides the services across a network.
- A service registry; that is a database containing the locations of all available service instances.
- A service consumer; who retrieves the service provider’s location from the service registry and communicates with the service instance.
Types of Service Discovery
There are two primary patterns of service discovery, client-side discovery and server-side discovery. They both have their own uses, advantages, and disadvantages. The primary difference is that in client-side discovery, the responsibility of finding available service instances lies with the client and in server-side discovery, the responsibility lies with the server.
Client-Side Service Discovery
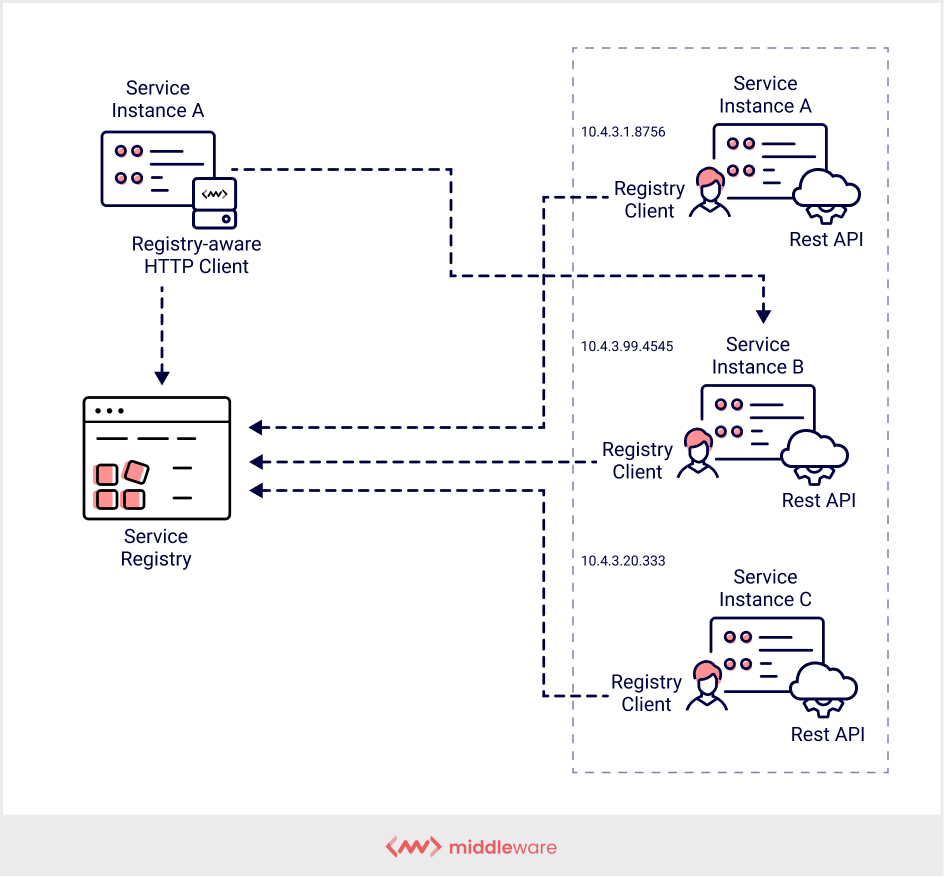
In this type of service discovery, the service client or consumer has to search the service registry in order to locate a service provider. Then, the client selects a suitable and free service instance through a load balancing algorithm to make a request.
In this pattern, the service instance’s location gets registered with the service registry as soon as the service starts. The location information is deleted after the service instance is terminated. This refresh occurs periodically using a heartbeat mechanism.
This type lets you make intelligent decisions regarding load balancing as the consumer remains aware of which service instances are available and capable of taking up the load. It is easy to understand and lets the client determine the network locations of available service instances.
The client’s first query is directed at a Discovery Server, which is a central server that acts as a phone book for all service instances that are available. It also provides a layer of abstraction to the service instances.
In client-side service discovery, the service might be placed behind an API gateway. If not so, it is the client’s responsibility to implement aspects such as authentication, balancing, and cross-cutting.
A popular example of client-side discovery is Netflix OSS, where the service registry is Netflix Eureka. It provides a REST API that manages the integration of service instances and querying available instances. Netflix Ribbon works with Eureka as an IPC client to deal with load balancing functions while requests are made to available service instances.
Advantages of Client-Side Service Discovery
There are several advantages to using the client-side service discovery pattern. It is simple, straightforward, and consists of no moving parts except the service registry. It also lets the client be in control of the load balancing decisions.
- The client can make intelligent decisions according to requirements.
- The load-balancing decisions can be application-specific, such as using hashing.
- It is less complicated and can be handled easily.
- It does not have to route the client application or request through a router or load balancer.
- It avoids the extra steps in the middle and results in a quick turnaround.
Disadvantages of Client-Side Service Discovery
This pattern also has its drawbacks.
- It couples the client with the service registry, which means the client-side discovery logic has to be implemented for each programming language and framework used by the service clients.
- It makes application management complicated as the microservices architecture works with diverse technologies, frameworks, and tools of different languages.
- The client has to make two calls to reach the target microservice.
Server-Side Service Discovery
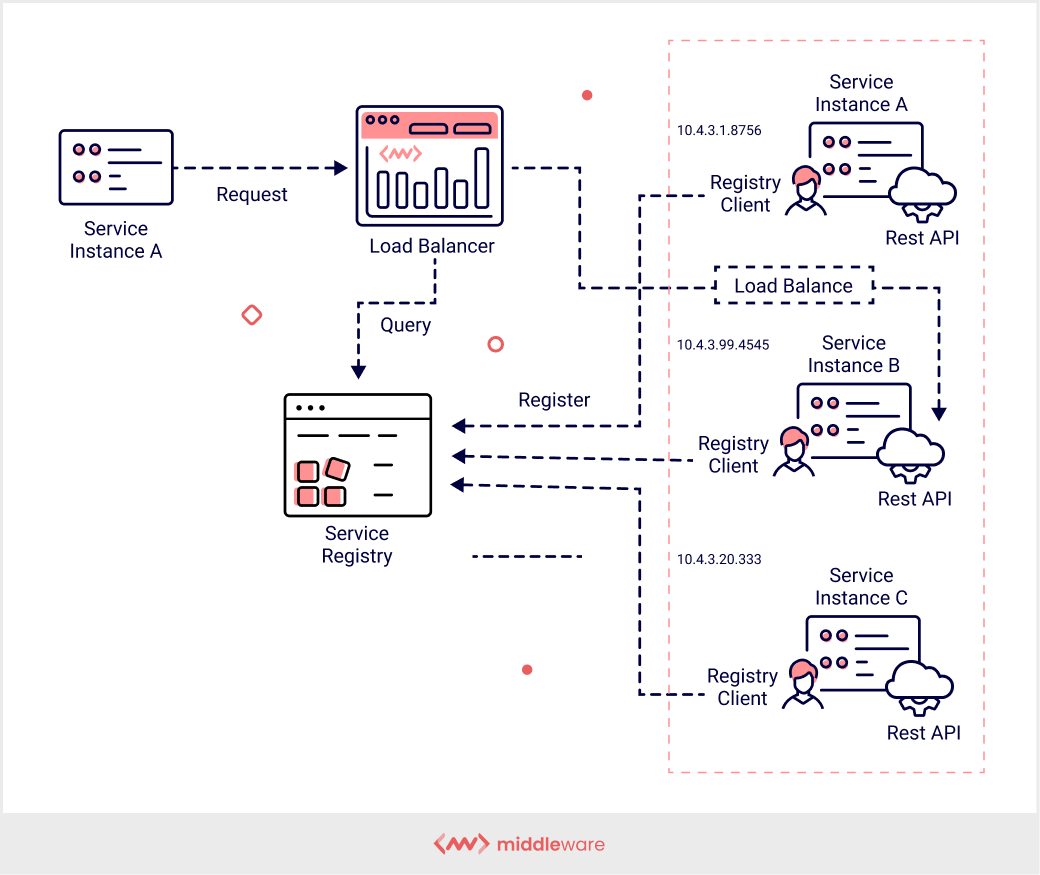
In this type of service discovery, the client or consumer does not have to be aware of the service registry. The requests are made through a router, which then searches the service registry itself. When the router finds a valid service instance that is available, it forwards the request and gets the job done.
In this pattern, the client does not have to worry about load balancing or finding a suitable service instance. Instead, this job is done by the API gateway, which selects the suitable endpoint for a request coming from the client’s side.
Basically, it is the server side’s server that is responsible for receiving the client server’s request and passing it along successfully. This is done by maintaining a registry of service locations and locating the client’s desired service without requiring any manual intervention from the consumer side.
Each client request is dealt with similarly by the load balancer. Similar to client-side discovery, the service instances are registered with the service registry when the service starts. As soon as the service is terminated, the service instance is deregistered.
A popular example of server-side service discovery is Amazon Web Services (AWS) Elastic Load Balancer (ELB). The ELB is used to balance the load of external traffic from the internet, as well as internal traffic directed to a virtual private cloud (VPC).
The client makes a request through the ELB using its DNS name. The request can be HTTP or TCP. The ELB then performs load balancing of the traffic among EC2 instances or EC2 container service (ECS) containers. The EC2 instances and ECS containers are registered directly with the ELB, without the existence of any separate service registry.
In some deployment environments, like Kubernetes and Marathon, a proxy is run on each host in the cluster. The proxy acts as a server-side load balancer and routes the request using the host’s IP address and the port assigned to the service. Then, the request is forwarded to an available service instance running in the cluster.
Advantages of Server-Side Service Discovery
The server-side discovery type has many benefits.
- It does not involve the client in exploring the details of finding an available service instance.
- It creates an abstract between the client and server-side.
- It removes the need to implement the discovery logic separately for each language and framework that the service clients use.
- It is available for free, with some deployment environments.
- The client needs to make only one call to request services, without having to be involved in looking up available instances.
Disadvantages of Server-Side Service Discovery
The disadvantages of service side discovery can be the following.
- It needs to be set up and managed by you unless already provided by the deployment environment.
- You need to implement the load balancing mechanism for the central server.
- It does not let the client choose a suitable service instance.
How to implement Service Discovery
Implementing service discovery might seem like an uphill task at first thought. However, there are several ways to achieve this implementation, based on specific requirements. Let’s discuss three ways in which you can perform service discovery implementation.
DNS-Based Approach
When you take the DNS approach to implement service discovery, you have to use standard DNS libraries as clients. In this type of implementation, each microservice has an entry in a DNS zone file. Then, it does a DNS lookup in order to locate an instance. Another way is to configure a microservice to use a proxy such as NGINX that can periodically poll the DNS for service discovery.
The DNS-based approach works with any programming language. It also works with no or minimal changes in the code. However, it also has certain disadvantages that need to be considered. You cannot get a real-time view with DNS, which means it gives insufficient support if different clients have different caching semantics.
It can also be an expensive option as it requires an operational overhead for managing zone files as new services keep getting added or removed. It also requires additional infrastructure for regular health checks and local caching when the central DNS server cannot be reached.
Key/Value Store and Sidecar Approach
In this approach, a consistent data store such as Consul or Zookeeper is used as the central service discovery mechanism. It uses a key/values store and a sidecar to communicate. The microservice communicates with the local proxy, and another process communicates with the service discovery. This information is used to configure the proxy and fetch results.
Consul offers numerous interfaces like REST and DNS to use with a sidecar process. The key/value store and sidecar approach are completely transparent to the coder. It lets the code be written in any programming language without having to worry about the feasibility of interaction among the microservice and other services.
However, the sidecar has limits regarding host discovery. It cannot route to more granular resources or schemes. It also adds an extra step for every microservice in the form of the sidecar. The sidecar needs critical maintenance as it must be tuned and deployed with every microservice.
Specialized Service Discovery Using Library/Sidecar
In this approach, a library is used by the developer to communicate with a specialized service discovery solution, for instance, Eureka. Here, the functionality is directly exposed to the end developer and thus they need to be aware of the fact that they are coding a microservice by calling APIs.
You can discover any resource through this approach as it is not limited to hosts. The deployment function is clear and straightforward, and the client library is deployed with other service libraries. This needs a broad set of client libraries that can support multiple programming languages.
The Service Registry
As mentioned earlier, the service registry is a key component of service discovery. It is a database containing the locations of all available service instances. Thus, it must be updated and regularly maintained.
Clients can store the network locations obtained from the service registry as cache, but they must not rely on it for long as the information quickly becomes outdated in this dynamic environment and the client is then unable to discover service instances.
A service registry is made of a cluster of servers that use replication protocol for consistency. Let us take the example of Consul by HashiCorp. Consul is primarily a tool to discover and configure services. Its API allows clients to register and discover service instances, and it also performs regular health checks to ensure service availability.
Consul’s centralized service registry helps discover services by storing location information in a single registry and adding functionalities, such as:
- Controlling the distributed data plane to provide a scalable and reliable service mesh.
- Providing a real-time directory of all running services.
- Automating centralized network middleware configuration to reduce human intervention.
- Automating lifecycle management of certificates issued by third-party Certificate Authority.
- Enabling visibility in services and their health status.
- Providing unified support across different workload types and runtime platforms.
Service Registration Options
Service instances need to be registered and deregistered with the service registry in all types of service discovery. To do that, there are a couple of service registration options. They are self-registration and third-party registration patterns. The names are self-explanatory regarding their methodology.
The Self-Registration Pattern
In this type of registration, the service instance takes care of registering and deregistering itself with the service registry. It can also send heartbeat requests to stop the registration from expiring while it is still in service. The Netflix OSS Eureka client uses the self-registering pattern as it handles all aspects of this task.
Self-registration is simple and does not depend on any other system components. It registers its address with the registry and immediately deregisters itself when the instance terminates. However, it does couple the service instances to the service registry, which means you must implement the registration code in each language and framework used.
The Third-Party Registration Pattern
The third-party registration pattern does not allow the service instances to register themselves. Instead, the register and deregister process is done by the service registrar, which is a system component that tracks changes to the set of running instances.
This is done by polling the deployment environment or subscribing to events. As soon as a newly available service instance is spotted, the registrar registers it with the service registry. It also deregisters terminated service instances automatically. Netflix OSS Prana is an example of this pattern. It is a sidecar application that registers and deregisters service instances with Netflix Eureka.
The benefit of third-party registration is that it decouples services from the service registry. This means you do not have to implement registration logic for every programming language or framework. Instead, registration is handled with a dedicated centralized service. However, this pattern is not built within the deployment environment. Thus, you need to set up and manage it.
Final Thoughts
A microservice application contains a cluster of running service instances with dynamic changes. These instances have dynamic network locations and need a system to communicate or locate. Thus, a client needs service discovery to make a request.
The service registry helps by providing a database of available service instances, along with the management API and query API. Through this, services can be discovered, registered, and deregistered based on usage. You can use the client-side discovery type or the server-side discovery type, depending on whether you want to set up the environment or automate it.



