If you work with automated testing long enough, you’ll inevitably run into that test that everybody side-eyes, the one that passes on Monday, fails on Tuesday, and then magically behaves again when you re-run the pipeline. No code changes, no config updates… just pure unpredictability. That’s a flaky test.
In fast-moving CI/CD setups, flaky tests are more than a minor annoyance. They interrupt release cycles, drain developer time, and slowly erode trust in your automation suite. And the worst part? They often show up when you least expect them, during a critical merge, a late-night hotfix, or right before a deployment window.
In this blog, we’re going to break down what flaky tests are, why they occur, how to identify them early, and steps to eliminate them. You will also see how stronger observability tools help teams gain deeper insights into test behavior and identify the root causes of instability.
🔹Learn how teams proactively detect failures and performance issues using synthetic monitoring
What is a Flaky Test?
A flaky test is unpredictable: it may pass or fail even when nothing has changed in the code or environment. These tests confuse CI/CD pipelines because they appear to be failures but behave erratically. We should first know why flaky tests are so widespread a phenomenon:
- Inconsistent results: passes and fails across runs with no actual code changes.
- Hard to reproduce: the failure often disappears when rerun locally or on another pipeline.
- Unreliable signal: makes it difficult to trust test results or spot real issues.

Types of Flaky Tests
Not all flaky tests fail for the same reasons. Categorizing flakiness helps teams quickly narrow down root causes and apply the right fixes. The most common types include:
- Timing-based flaky tests: These occur when tests rely on assumptions about execution speed. Asynchronous operations, delayed UI rendering, or slow API responses can cause intermittent failures when timing conditions aren’t explicitly handled.
📌Discover how browser-based synthetic tests help monitor real user journeys and reduce UI test flakiness
- Order-dependent flaky tests: Some tests pass or fail depending on execution order. This usually happens when tests share state, data, or resources and do not clean up properly after execution.
- Environment-dependent flaky tests: Tests that behave differently across local machines, CI runners, or cloud environments. Variations in CPU, memory leaks, network latency, or OS versions often trigger these failures.
- Data-dependent flaky tests: Tests that rely on random, stale, or non-deterministic data can produce inconsistent outcomes. Leftover database records or randomly generated inputs are common contributors.
- Infrastructure-induced flaky tests: Resource contention, container throttling, or transient network issues can cause tests to fail even when application code is correct.
Understanding which category a flaky test falls into significantly shortens investigation time and prevents misdirected fixes.
Why Flaky Tests Are a Problem
Flaky tests not only inconvenience engineers, but they also disrupt the entire flow of a rapid CI/CD line. Once the test is passed at one minute and the following one is failed due to no apparent reasons, the reliability of the automation reduces. These tests do not accelerate releases but decelerate everything. What is so significant about flaky tests:
- They undermine the confidence in automation: When a developer observes a test failing sporadically, he/she ultimately lose faith in it. All red builds are treated as false alarms, and actual problems can slip through because no one knows which failures are significant.
- They slow down CI/CD pipelines: a few unstable tests can halt merges, trigger unwanted reruns, and roll back releases by hours or days. The pipeline is made slower, noisier, and less reliable, the complete opposite of what a good CI/CD pipeline is supposed to be.
- They add to the workload of engineering teams: Each flaky failure takes somebody into a rabbit hole-code, test or environment? Multiplied by dozens of intermittent failures over a week, that is a big portion of engineering time spent in debugging non-existent problems.
- They distort your metrics and observability: Unstable test results indicate that dashboards and failure modes begin to tell a false story. It is more challenging to measure stability, regression spots, and quality. Tools such as Middleware bridge this divide by linking test failures to system performance, allowing teams to determine whether a failure is absolute or merely another flaky outlier.
- They accumulate in the form of technical debt: the more loose tests you have ignored, the weaker your test suite becomes. This gradually slows down the whole delivery pipeline and increases the risk of releasing new features.
✅Learn how combining Core Web Vitals with RUM and synthetic monitoring helps differentiate flaky tests from genuine performance regressions
The Hidden Cost of Flaky Tests
Flaky tests introduce more than momentary frustration; they carry measurable operational and business costs.
Each intermittent failure forces engineers to stop feature work, re-run pipelines, and investigate issues that often turn out to be false alarms. Over time, this context switching slows delivery velocity and increases CI infrastructure costs due to repeated test executions.
More importantly, flaky tests erode trust in automation. When teams start assuming failures are “probably flaky,” real regressions can slip through unnoticed. This silent risk makes flaky tests more dangerous than consistently failing tests, which at least provide a clear and reliable signal.
Want to reduce noisy alerts and focus on meaningful signals? Learn how observability best practices help teams cut noise and improve system reliability.
Common Causes of Flaky Tests
A single problem does not cause flaky tests; in most cases, they result from multiple minor inconsistencies colliding. They can result from timing glitches, environmental instability, dependency failures, or test design flaws. Knowledge of these underlying causes enables teams to build strong, predictable, and reliable test suites across CI/CD pipelines.
1. Timing Problems & Race Conditions
Tests involving asynchronous behavior, including slow API response times, delayed element loading in the UI or background jobs, tend to produce erratic behavior. Waits are hard-coded, not synchronized, or assume a fixed execution speed, resulting in passing the test once and failing the next time.
Example: A test clicks a submit button after filling in a form and sometimes the validation api has not returned, and it leaves the submit button as disabled, causing random failures.
→ Learn how to configure synthetic monitors (including response thresholds and assertions) to detect unavailable or slow endpoints proactively.
2. Concurrency & Shared Resource Conflicts
Parallel tests that share files, databases, queues, or global state can interfere with each other. Failures surface only under specific execution orders or system loads, making them hard to reproduce locally.
Example: Test_CreateUser and Test_DeleteUser both run in parallel. If Test_DeleteUser fires before the user is created, it fails; if the order is reversed, it passes, resulting in a flaky outcome.
3. Unstable or Inconsistent Test Environments
Differences in CPU, memory, network speed, OS versions, or CI agent resources can produce different outcomes for the same test. Cloud-based runners, especially those with variable resource allocation, amplify this inconsistency.
Example: A UI test that passes locally on a powerful dev machine fails in CI because the CI container has less memory, causing rendering delays or timeouts.
4. External Dependencies Causing Intermittent Failures
Tests relying on third-party APIs, authentication systems, external databases, or integrations can fail due to latency, rate limits, or service downtime, issues unrelated to your actual code.
Example: A test calls a remote payment API. If the API is rate-limited or temporarily down, the test fails, even though your own code is fine.
5. Weak or Poorly Structured Test Design
Flaky tests often stem from unclear setup/teardowns, inconsistent data usage, testing too many behaviors at once, or combining multiple assertions in a single test. These design flaws introduce variables that cause inconsistent behavior.
Example: A test generates a random username each run but doesn’t reset or parameterize the random seed. Sometimes the random data generates invalid states, causing the test to fail unpredictably.
6. CI/CD Pipeline Configuration Issues
Flaky tests are not always caused by test code. The CI pipeline configuration itself can introduce instability.
Common pipeline-level causes include:
- Overloaded or under-provisioned CI runners
- Excessive parallelization without proper isolation
- Shared caches or persistent volumes between jobs
- Non-ephemeral environments carrying leftover state
Because these issues often surface only under load, they can be difficult to reproduce locally and require infrastructure-level visibility to diagnose effectively.
Example: A UI test consistently passes on a developer’s machine but intermittently fails in CI due to timeouts. The investigation reveals that multiple jobs share a single CI runner, causing CPU throttling and delayed page rendering during peak load.
Identify Flaky Tests in Your Pipeline
You should identify which tests will fail as soon as possible to maintain a steady, reliable CI/CD pipeline. Flakiness occurs only under certain conditions; therefore, it is difficult to detect during manual runs alone.
Since flaky failures occur occasionally, consistent monitoring, pattern identification, and automated systems are required to detect them with high reliability. This enables you to identify actual failures and random test noise, and to prevent flaky tests that halt development and corrupt pipeline observations.

1. Rerun Tests to Confirm Consistency
One of the simplest detection methods is to run the same test multiple times. If it passes and fails across repeated executions without any code changes, it’s a strong sign of flakiness and needs deeper analysis.
2. Leverage CI/CD Analytics & Flakiness Detection Tools
Platforms like Datadog CI Visibility, BuildPulse, and the Jenkins Flaky Test Plugin automatically analyze failure patterns and test history. Tools like Middleware go further by correlating test results with system performance, helping teams link intermittent failures to environment issues, resource spikes, or dependency latency.
3. Review Historical Execution Data
Examining long-term trends helps uncover tests that fail only on certain branches, specific runners, or under particular load conditions. These patterns reveal whether failures are genuine or merely inconsistent behavior driven by external factors.
4. Quarantine Unstable Tests Temporarily
Once a flaky test is detected, move it to a quarantine suite. This prevents it from blocking builds while still allowing engineers to analyze and fix the underlying issue. Quarantining keeps the main pipeline clean and prevents “false alarm” failures.
5. Separating Signal from Noise in Test Failures
A single failed test does not always indicate a flaky test, but repeated, inconsistent failures do. The challenge lies in distinguishing real regressions from background noise.
Patterns that often indicate flakiness include:
- Tests that fail intermittently across multiple runs
- Failures are limited to specific CI runners or environments
- Correlation between failures and system load, memory pressure, or network latency
- Tests that consistently pass when re-run without changes
Observability-driven analysis helps teams move beyond pass/fail results and understand why a test failed under specific conditions, restoring confidence in test signals.
Test Retries – Helpful or Harmful?
Retrying failed tests is a common practice in CI pipelines, but it can be both helpful and harmful.
Retries may reduce short-term pipeline noise, especially for non-critical tests affected by transient issues. However, excessive reliance on retries can mask underlying problems and allow flaky tests to persist unnoticed.
A retry should be treated as a diagnostic signal, not a solution. Tests that frequently pass only after retries are strong candidates for investigation and remediation. Tracking retry frequency over time helps teams identify instability before it becomes systemic.
Still rerunning pipelines to “see if it passes”?
That’s often a sign of flaky test noise hiding real issues.
Fixing & Preventing Flaky Tests
Here are some actionable strategies to stabilize your test suite and prevent flakiness from creeping back in:
- Designing Tests That Don’t Become Flaky: Preventing flaky tests starts at design time, not after failures appear.
- Improve synchronization: Use explicit waits, proper polling, and controlled timing instead of fixed sleeps. Make sure tests wait for the real conditions (e.g., element visible, API response) before proceeding.
- Use mocks or stubs for external dependencies: Replace unstable third-party services or flaky APIs in your tests with controlled mocks or stubs in CI. That isolates your tests from external variability.
- Reset data (state) between test runs: Clean up your database, session, or any shared state before and after each test run. This ensures that no leftover data from previous runs introduces randomness.
- Ensure consistent test environments: Run your tests in standardized, isolated containers or ephemeral environments so variability in OS, CPU, or memory doesn’t cause random failures.
- Monitor test results and automate flakiness detection: Continuously track test outcomes, flag unstable tests, and take action (retry, quarantine, or fix) instead of ignoring them.
⚙️Many flaky tests can be avoided by validating stability earlier in the development lifecycle. Learn how shift-left testing helps teams catch issues before CI pipelines fail
How Middleware Helps with Flaky Test Prevention
When a synthetic test fails, Middleware correlates that failure with backend traces, infrastructure metrics, and logs from the same time window.
This allows teams to determine whether a failure was caused by application logic, a slow database query, a saturated service, or an external dependency.
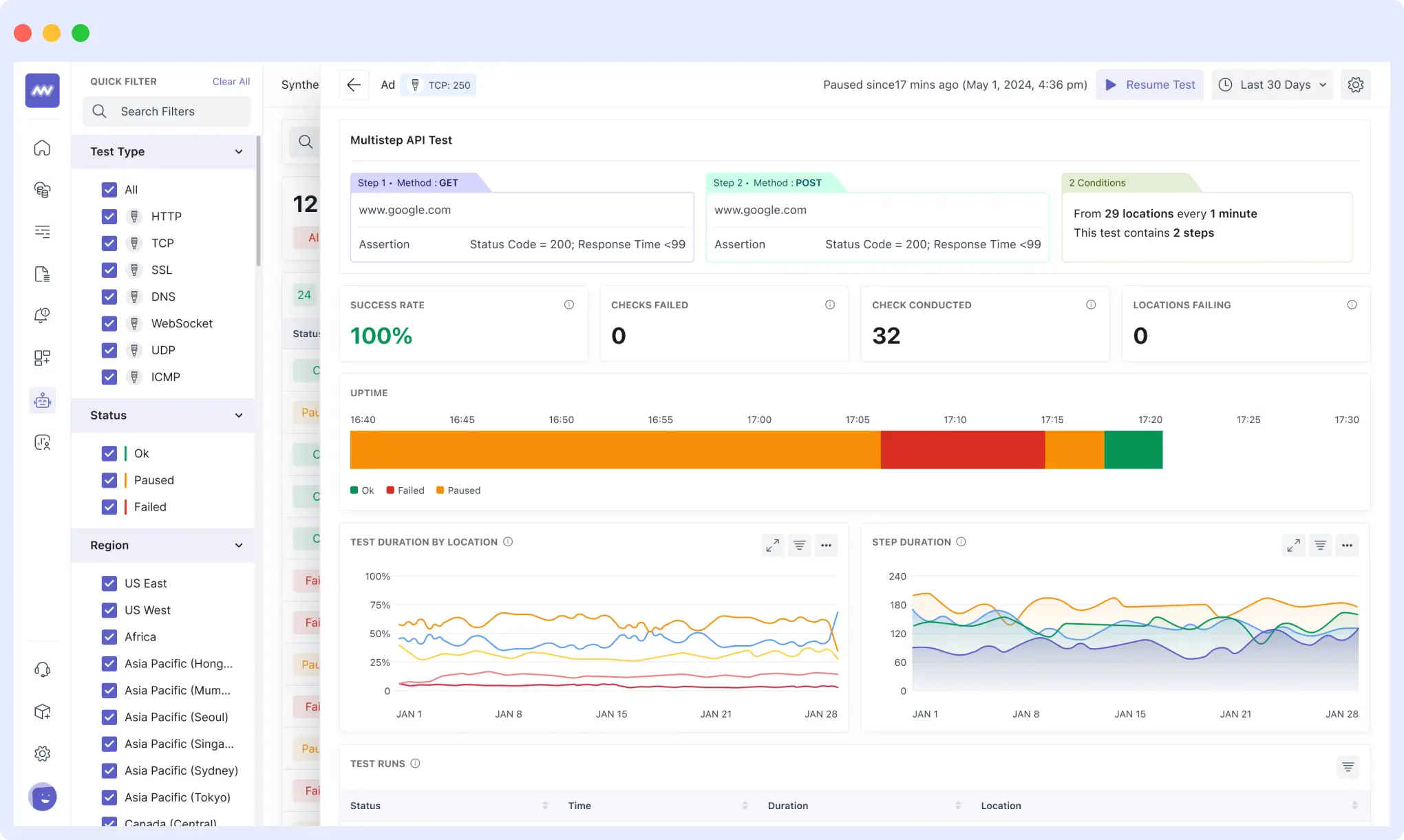
Moreover, Middleware links synthetic test failures to distributed traces, providing you with end-to-end context.
A failed test immediately identifies the backend service, API call, or database query that caused the problem, allowing you to correct the underlying cause rather than simply suppressing the wobbling indicators.
Ownership and Accountability for Test Stability
Stable test suites require clear ownership. Teams that successfully reduce flakiness treat flaky tests as a distinct class of technical debt, with defined owners and remediation expectations.
Standard practices include assigning responsibility for test stability, tracking flaky tests as first-class issues, and setting internal SLAs for fixing or refactoring unstable tests. This accountability ensures flakiness is addressed systematically rather than ignored.
Here are some best practices to foster that mindset:
- Make quality everyone’s responsibility; developers, QA, and DevOps should all be accountable for test stability.
- Use data and metrics to visualize test flakiness, failure rates, and test coverage in dashboards so teams can see the cost of unreliable tests.
- Create feedback loops, hold retrospectives to analyze flaky test failures, encourage team discussions around root cause, and address instability in a blameless way.
Experience smarter flaky-test diagnosis. Start your free trial or book a demo to see how Middleware’s monitoring helps you detect, analyze, and fix flakiness with confidence.



