
For decades, traditional ITOps have been the norm. They have accomplished their goals, but they use inefficient methods for complex tasks. For example, teams handle incident responses manually. The new age of AI has brought us a changing approach to IT Operations (ITOps) called AIOps.
Using artificial intelligence and machine learning, it aims to automate, streamline and enhance IT operations. It transforms manual workflows into smooth and predictive processes.
We’ll cover everything you need to know about AIOps, enabling you to replace your traditional IT operations processes confidently.
What is AIOps?
AIOps is an AI-driven approach to traditional IT operations. Just like ITOps, AIOps also works on top of various data, such as logs, metrics, traces, events, etc. The goal is the same: use log files to spot errors, metrics to track performance, and events to diagnose system failures.
To deepen your understanding of how to assess and improve your observability setup, check out Observability Maturity Model. This framework guides you through enhancing your monitoring and alerting capabilities.
However, at its core, AIOps uses a different approach that essentially consists of four components:
- Data Ingestion: This process helps to collect all the required data points from several diverse sources that can be helpful for incident management and building reports.
- Machine Learning: The data collected in the previous process is fed to a trained machine learning algorithm to recognise log patterns.
- Pattern Recognition: At this step, the system identifies trends, detects anomalies, and predicts future issues and points of failure.
- Automation: In the last step, the system takes automated actions based on insights from the previous two steps.
How AIOps Works?
To effectively incorporate AIOps into your IT operations, it’s essential to understand the underlying mechanisms and use the knowledge of how AI and ML can enhance operational efficiency.
Let’s look at all the steps that happen in the working of AIOps:
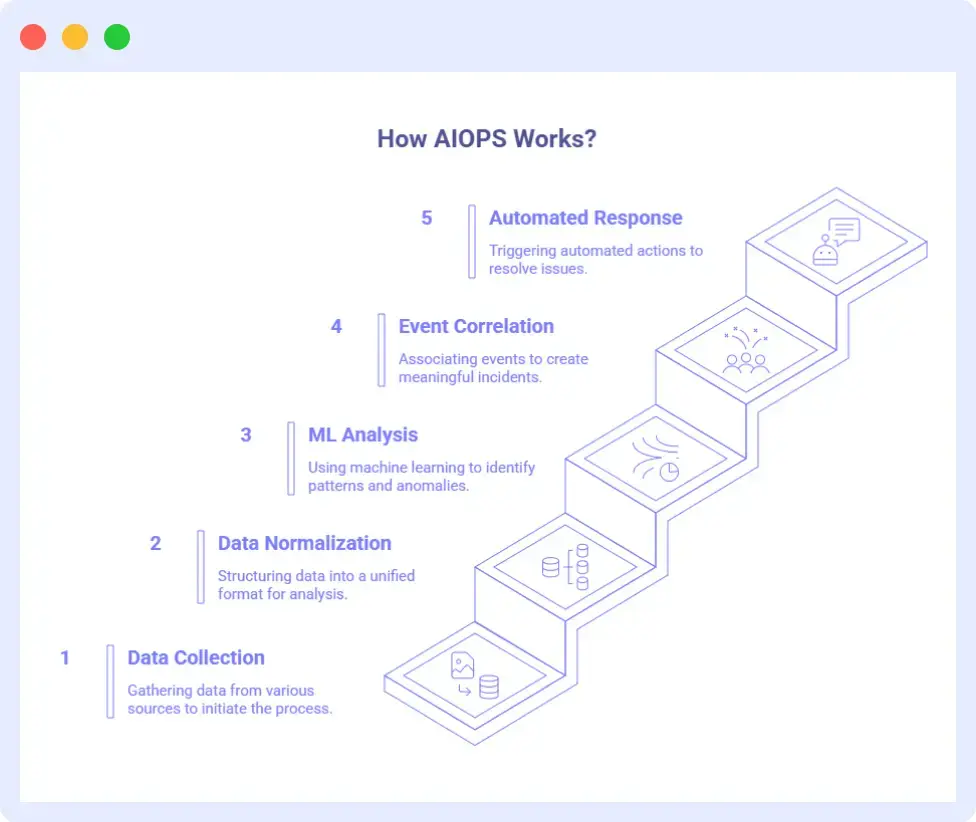
Data Collection
The first step in AIOps is collecting data from various sources. These sources include servers, applications, cloud infrastructure, and other related components.
Take, for example, an e-commerce platform. It collects logs from transactions, customer databases and network infrastructure. This entire process entails data collection.
Data Normalisation and Correlation
Once the system collects data, it normalises and structures it into a unified format. This allows AI to correlate data from different sources.
For example, AIOps might correlate slow response times from your application logs with high CPU usage, as indicated by metrics collected from the servers. Normalisation helps facilitate correlation, which in turn enables you to detect patterns and anomalies.
Machine Learning Analysis
AIOps uses integrated machine learning algorithms to sift through correlated data, spotting patterns and flagging anything out of the ordinary.
These discoveries are crucial for identifying and resolving performance glitches and critical app performance issues. They can also help you identify possible solutions.
For instance, a sudden spike in traffic causing increased load times can be quickly identified as abnormal behaviour.
Event Correlation and Root Cause Analysis
In one of the previous steps, the system correlates data to create events. Then it associates multiple events to form meaningful incidents. This process, called incident management, helps reduce alert fatigue.
Next, the system performs root cause analysis to identify the underlying issue. Let’s say AIOps identifies that a database query bottleneck is causing application latency.
Automated Response and Remediation
Finally, AIOps can fix issues on its own! After analysing everything and offering insights on top of the patterns, it can trigger automated responses to solve the problems.
All of this without the need for manual intervention of a single engineer from your team.
It can automatically scale up resources to handle more load and prevent downtime, saving your crucial time that can be invested elsewhere.
Automation isn’t just about saving time. it’s about enabling your team to focus on innovation while your systems fix issues automatically.
Why AIOps Matters
Traditional ITOps has worked well for decades for enterprises both big and small. However, they may be outdated and bring their own set of challenges:
Drawbacks of Traditional ITOps
- Data overload: Every day, thousands of logs and alerts are generated. Filtering through them to understand the relevant alerts and figuring out action items becomes overwhelming and almost impossible.
- Increased complexity: Modern IT environments are more than just a self-hosted monolith; they could be SaaS, have microservices, or may have even more complex architecture.
- Reactive incident management: Incident management with traditional ITOps typically happens after the incident has occurred and users are affected. This is inefficient and degrades trust in your customers.
AIOps aims to effectively tackle the above-stated challenges by offering the following advantages.
Advantages of AIOps
- Proactive issue detection: By using pattern recognition, it can predict and highlight potential future issues so you can mitigate them before they even impact your users.
- Faster mean-time-to-resolution (MTTR): AIOps extensively relies on automation, which can speed up the MTTR time required to debug and diagnose an issue and offer a resolution.
- Enhanced operational efficiency: With automation in place, you can not only execute the IT operations faster, but can also accommodate more time for other critical tasks in your organisation, boosting your overall operational efficiency.
- Improved end-user experience: With proactive management, where you catch issues before they occur, your users experience a seamless and uninterrupted experience of using your application.
Trademarkia reduced their time to resolution by 20% and improved developer productivity by 25% using Middleware’s full-stack observability platform. Learn how they streamlined issue detection and resolution
Middleware’s Ops AI in Action
OpsAI helps identify issues across your entire Middleware observability stack. This means any logs collected from your application, infrastructure, frontend, etc, will be used to determine the problems without the need for any additional tools.
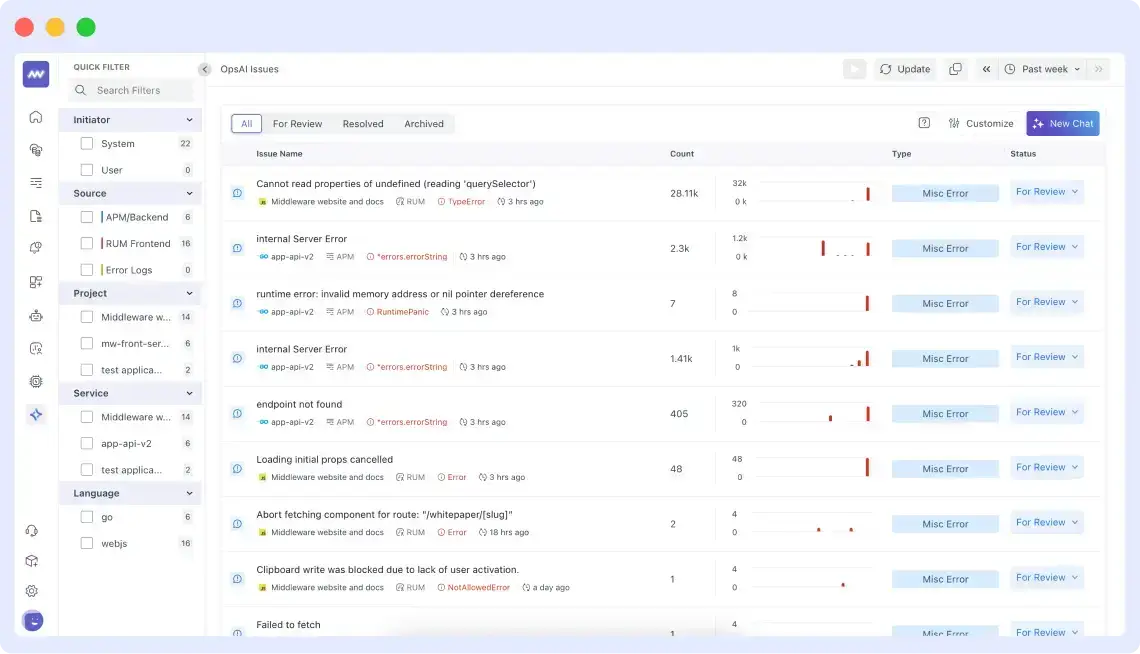
If you click on an issue, you can see the suggested solution by OpsAI. Using context from your previous commits, dependencies and similar errors that may have occurred in the past, it can suggest accurate solutions to resolve the issue.
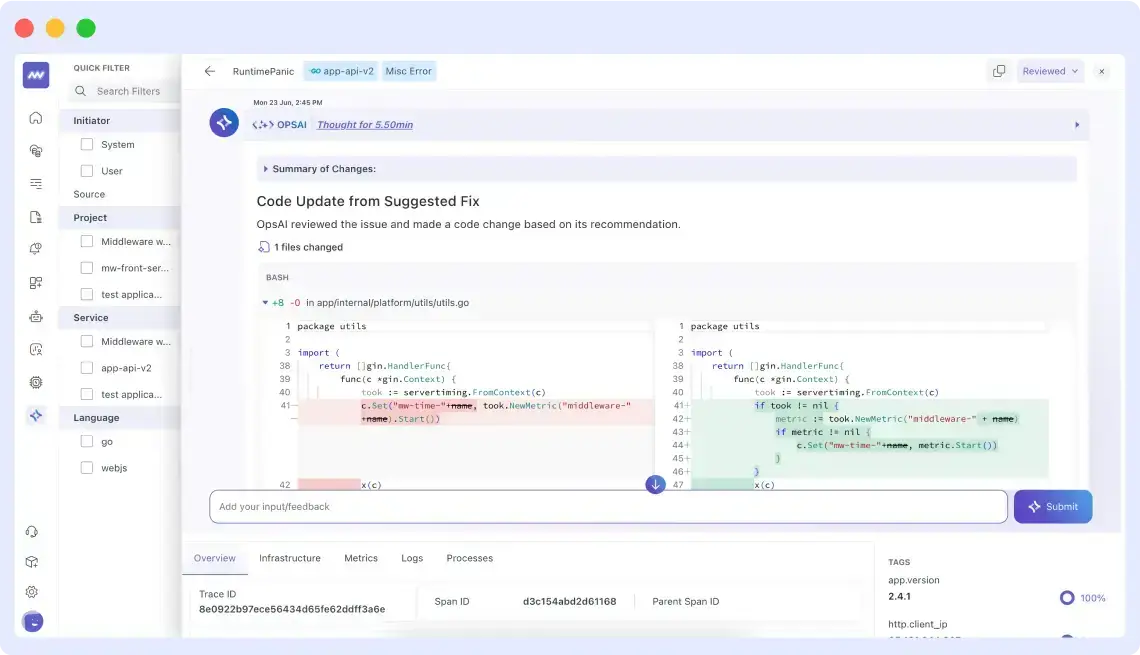
With a one-click action, you can commit the fix by creating a new PR without leaving the Ops AI interface. However, this action is only available if OpsAI is at least 95% confident that the fix will work.

Otherwise, it gives you a good starting point with its suggested fix that you can further iterate upon.
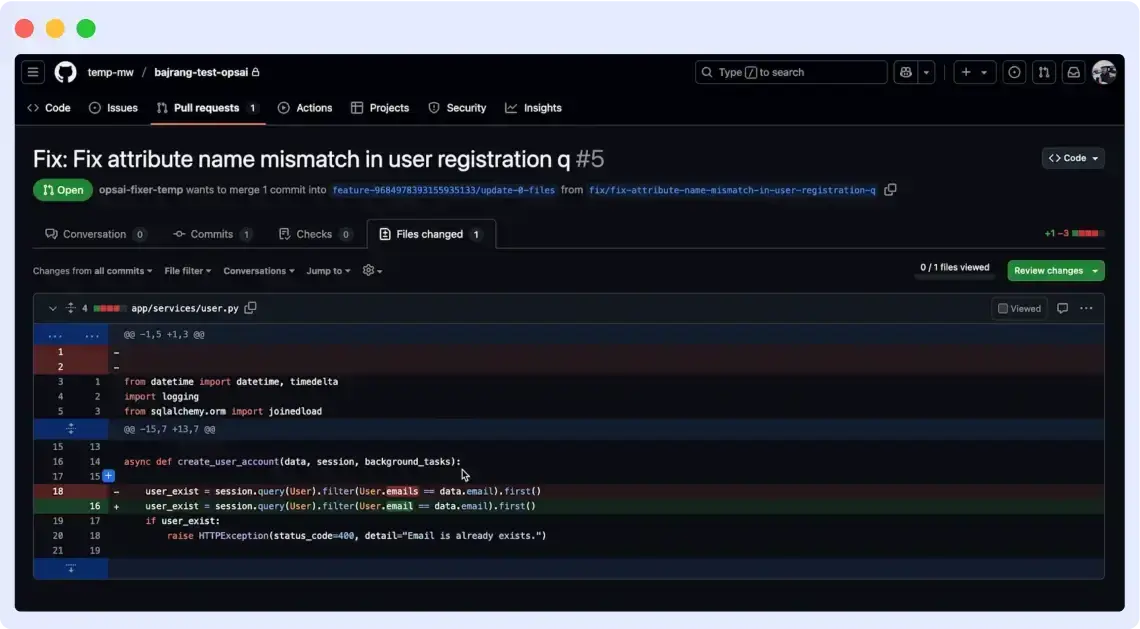
OpsAI is like GPT or a cursor for all your observability needs, right from identifying issues, to narrowing down root cause, to creating PRs and deploying fixes.
Key Capabilities of AIOps
Now let’s explore some specific AI-driven capabilities that OpsAI provides and some practical scenarios where these capabilities can be helpful.
Integration and Ease of Use
Middleware’s Ops AI can seamlessly integrate with your existing infrastructure, including standard monitoring tools like AWS, Azure Monitor, Prometheus, etc. You can deploy Middleware’s Ops AI in minutes on Kubernetes without the need for any extensive configuration.
⚡ Deploy Middleware’s Ops AI in minutes and get real-time insights into your Kubernetes clusters.
👉 Start Monitoring Now
Moreover, it can also pull essential data in real-time from your Kubernetes system. With an easy-to-use and intuitive interface, you can create custom dashboards in no time, where you can see all your metrics and alerts and jump directly to incidents from the dashboard.
These integration capabilities and ability to swiftly navigate the platform can streamline your IT operations.
Auto-remediation
Kubernetes cluster pods failing is a frequent issue that many organisations encounter from time to time. While it can happen due to a number of reasons, often a lack of sufficient resources is the culprit behind it.
Ops AI can detect Kubernetes pod errors, such as crash loopback errors, in real-time and correlate them with your Kubernetes events, including node health issues. This gives you a clear idea of not only what the problem is, but its likely cause as well.
It can then automatically trigger a workflow that can potentially fix the problem. For example, in this case, Ops AI can restart the failed pods or even scale the insufficient resources provided it has the necessary permissions.
Automate Incident Response with Auto-Remediation
⏱️Reduce downtime and manual work by automating fixes with Middleware’s auto-remediation features. 👉 Try Now
In the absence of OpsAI, all of the above steps would have to be manually performed by your SREs and DevOps teams. With auto-remediation, OpsAI has significantly reduced potential downtime and freed your team from manual intervention to resolve these issues.
Predictive Insights
Imagine that you’re continuously pushing updates through your existing CI/CD pipeline. By forecasting potential performance bottlenecks, you can determine if these deployments will consume more resources than you currently have and scale them in advance to prevent deployment failures.
OpsAI provides visibility into your system and infrastructure’s health and resources, enabling you to plan and avoid disruptions.
Another typical example is when your application is experiencing severe spikes in traffic and usage. By proactively alerting you about CPU usage spikes, Ops AI can help you enable preemptive resource allocation and prevent performance degradation during such critical periods.
This guide explains how Application Performance Monitoring contributes to overall system health and performance.
Alert Deduplication and Intelligent Alerting
With hundreds of microservices interacting daily, organisations often get overwhelmed with a huge number of alerts that create noise and distract their team from what’s truly important.
Redundant alerts divert your team’s focus and destroy crucial engineering bandwidth, but they also make it harder to identify relevant alerts.
Ops AI’s intelligent alerting helps you filter these alerts. The built-in Machine learning models detect redundant and false positive alerts and group them into a single alert.
This helps reduce alert fatigue in your organisation, making room for priority incidents that actually require your attention.
Future Trends in AIOps
With technology evolving at the speed of light, some key trends are bound to shape the future of AIOps.
Generative AI adoption can introduce more advanced AI models to generate insights, provide more robust automation and assist in even more nuanced analysis, giving a comprehensive ITOps capability.
With algorithms improving every day, forecasting incidents is going to become more accurate, which in turn will help organisations make their systems even more error-proof. Finally, as emerging AI technologies like agentic workflows and real-time analytics readily start integrating with AIOps, it can truly become the new norm for modern IT operations.
FAQs
What is the difference between AIOps and DevOps?
AIOps makes use of artificial intelligence and machine learning algorithms to automate and enhance IT operations, whereas DevOps facilitates collaboration between development and IT operations teams to strengthen software delivery. AIOps can help boost the operational efficiency of a DevOps system.
Can AIOps replace human operators?
Rather than replacing humans, AIOps complements human operators by enabling them to focus on higher strategic-level critical tasks and automating repetitive tasks.
Is AIOps suitable for small teams?
Yes, AIOps can significantly benefit both big and small teams by automating routine tasks and improving efficiency. Using a lightweight, user-friendly solution like Middleware’s Ops AI, teams of all sizes can easily enable AIOps.
How does Middleware’s Ops AI compare to other AIOps tools?
Middleware’s Ops AI stands out due to its easy deployment, advanced automation, and intuitive user experience. Compared to other tools like Datadog, Splunk, Dynatrace, and New Relic, Middleware offers deeper contextual insights and streamlined integration with existing tools.
📚 Also Read
- Ops AI: Your AI Observability Co-Pilot: Discover how Ops AI can drastically reduce your MTTR and automate incident resolution.
- Top 10 Kubernetes (K8S) Troubleshooting Techniques: Learn practical ways to troubleshoot common Kubernetes issues effectively.



