
TL;DR
- Middleware earned G2 recognition based on verified reviews from DevOps engineers and SREs at organizations ranging from startups to enterprise IT.
- The most cited benefit is unified observability replacing three to five siloed tools with a single correlated view of logs, metrics, traces, and RUM.
- Native OpenTelemetry integration covers Go, Python, Java, and other languages without custom instrumentation overhead.
- Transparent pricing delivers measurable cost savings versus host-based alternatives like Datadog and New Relic.
- OpsAI, Middleware’s AI-powered incident triage assistant, helps teams reach root cause without switching tools even at 3 AM.
- G2 badges require verified user reviews that meet strict quality thresholds; this recognition reflects real practitioner outcomes, not marketing claims.
When thousands of software buyers evaluate observability platforms on G2, one question drives every decision: does this tool actually deliver? Middleware’s G2 recognition answers that question with verified proof from the teams using it daily.
Choosing an observability platform is high-stakes. Pick wrong, and your team drowns in tool sprawl, alert fatigue, and endless context-switching during incidents. The market is crowded with promises, but third-party validation cuts through the noise.
This post breaks down exactly why Middleware earned G2 recognition, using direct evidence from verified users who stake their production environments on the platform every day.
What G2 recognition actually means for buyers
G2 badges aren’t participation trophies. They’re calculated from verified user reviews, market presence, and satisfaction scores collected from real practitioners. When a platform earns recognition on G2, it means enough users took time to document their experience and those experiences met strict quality thresholds set by G2’s scoring methodology.

For DevOps teams and SREs evaluating observability tools, this matters. You’re not just buying software; you’re betting your incident response capability on a vendor. G2 recognition signals that other engineering teams have already run that experiment and reported positive outcomes.
The reviews driving Middleware’s recognition reveal consistent patterns: unified visibility, reduced tool sprawl, and faster mean time to resolution. These aren’t marketing claims. They’re documented experiences from practitioners at organizations ranging from startups to enterprise IT services.
Understanding why Middleware earned this recognition requires examining what real users report solving with the platform. The sections below break down the specific capabilities users cite most frequently.
Unified observability eliminates tool sprawl
The most consistent theme across Middleware reviews is consolidation. Teams describe moving from three, four, or five separate tools into a single platform that correlates logs, metrics, traces, and real user monitoring automatically.
This consolidation solves a concrete operational problem. During incidents, engineers waste critical minutes switching between tabs, mentally correlating timestamps across tools, and trying to reconstruct the chain of events. Unified observability eliminates that cognitive overhead.
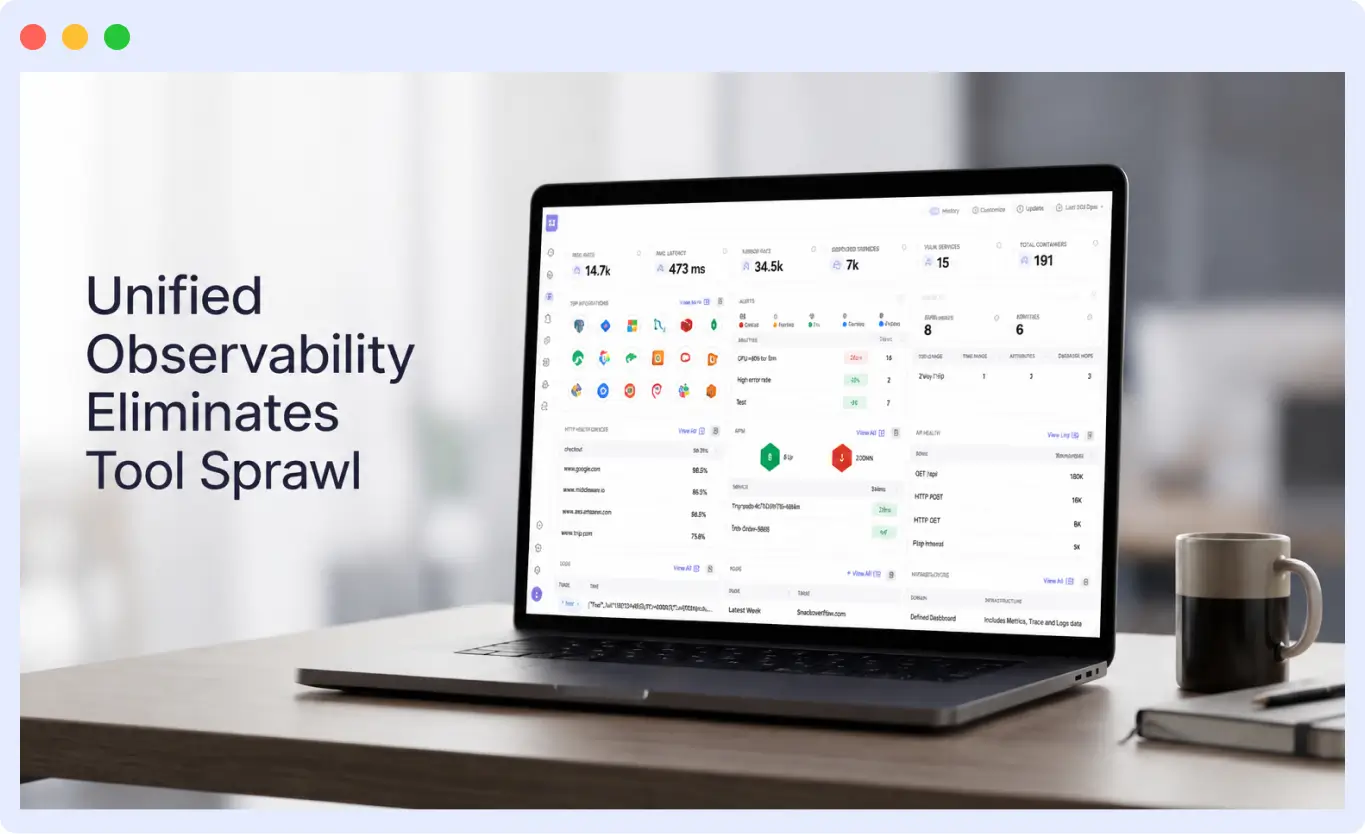
The practical impact shows up in incident response metrics. When all telemetry lives in one correlated view, the path from alert to root cause shortens dramatically. Teams report reduced MTTR and less stressful on-call rotations as direct outcomes.
Beyond incident response, unified visibility improves capacity planning and performance optimization. Decision-makers can see infrastructure health, application performance, and user experience in context making it easier to prioritize engineering investments based on actual impact.
“The biggest problem for us was the ‘tool sprawl.’ During an incident, our team would have five different tabs open — one for logs, one for application traces, one for server metrics, and so on. It was a digital wild goose chase trying to manually connect the dots between them all.”
— DevOps Engineer at Mood Indigo IIT Bombay
Middleware’s unified infrastructure monitoring and APM are built to address exactly this scenario one platform, one context, zero tab-switching.
OpenTelemetry integration simplifies instrumentation
For teams investing in observability standards, OpenTelemetry compatibility is non-negotiable. Middleware’s native integration with the OpenTelemetry ecosystem appears repeatedly in user reviews as a key differentiator.
The value proposition is straightforward: generate OTel-compliant metrics, logs, and traces without extensive custom instrumentation work. This matters for organizations running polyglot stacks across Go, Python, Java, and other languages. Instead of maintaining separate instrumentation approaches per language, teams get consistent telemetry collection.
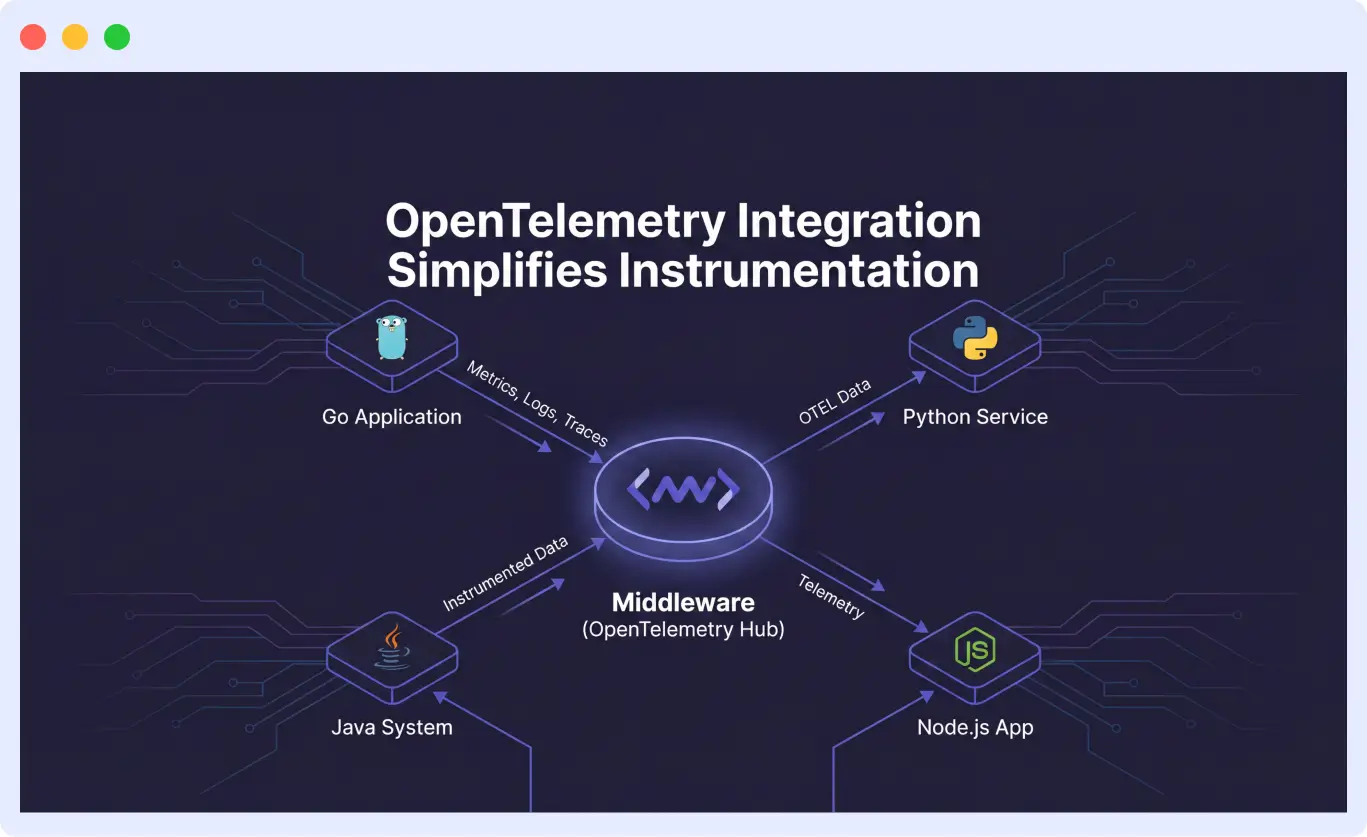
This standardization reduces vendor lock-in risk. Data formatted to OpenTelemetry specifications remains portable. If requirements change, the instrumentation investment isn’t lost. For engineering leaders evaluating long-term platform decisions, this flexibility carries significant weight.
Users also highlight that this approach covers multiple observability domains: database monitoring, infrastructure health, application logging, and APM. The result is a comprehensive solution built on open standards rather than proprietary formats that create future migration headaches.
“The best part of Middleware is its integration with the OpenTelemetry ecosystem. The ease of using Middleware in generating OTel-compliant metrics without the hassle of instrumenting code, and native integration with all the languages like Go, Python, and Java, is something that I find very useful for observability needs — it provides a one-stop solution for all observability needs.”
Engineer at Mitra AI
See how Middleware’s OpenTelemetry integration works across your entire stack.
Transparent pricing delivers measurable cost savings
Observability costs can spiral unpredictably, especially with host-based or data-volume pricing models. Users consistently mention Middleware’s pricing transparency as a factor in their evaluation and ongoing satisfaction.
The business impact extends beyond predictable invoices. Lower observability spend compared to alternatives like Datadog or New Relic frees budget for other engineering priorities. Teams report measurable cost savings while maintaining or improving their monitoring capabilities.
This matters particularly for growing organizations. Pricing models that penalize scale create perverse incentives: teams may reduce instrumentation coverage to control costs, exactly when growing infrastructure needs more visibility. Transparent, predictable pricing removes that tension.
Users note that advanced features like extended data retention or compliance-grade SLAs may require enterprise tiers. This trade-off appears reasonable to most reviewers, who appreciate knowing the cost structure upfront rather than discovering hidden charges after deployment.
“Lower observability spend compared to host-based pricing has delivered measurable cost savings.”
Engineer at Impero IT Services Pvt. Ltd.
Compare Middleware’s approach on the pricing page, or check out the Datadog pricing breakdown to see why teams are switching.
AI-powered incident triage accelerates resolution
Modern observability platforms increasingly incorporate AI capabilities to help teams navigate complex incidents faster. Middleware’s OpsAI assistant appears in reviews as a practical tool for incident triage and root cause analysis, not a gimmick bolted on after the fact.
The use case is specific: when an alert fires at 3 AM, engineers need to quickly understand what’s happening and why. AI-assisted triage surfaces relevant context, correlates related events, and suggests investigation paths, reducing cognitive load during high-stress situations.
Users report that OpsAI helps them reach root causes without switching between multiple tools or manually querying different data sources. The assistant works within the unified platform, leveraging correlated telemetry to provide contextual recommendations.
For teams managing complex distributed systems, AI assistance is a practical productivity multiplier. It doesn’t replace engineering judgment, but it accelerates the information-gathering phase of incident response when speed matters most. Middleware’s internal data shows OpsAI resolving over 50% of incidents automatically, with beta customers seeing 70%+ auto-resolution rates and 80%+ improvement in on-call productivity.
“Features like OpsAI (the AI-powered assistant) help us quickly triage incidents and get to root causes without switching tools.”
Engineer at Impero IT Services Pvt. Ltd.
Learn more about how OpsAI automates incident response for modern SRE and DevOps teams.
Intuitive interface reduces onboarding friction
Powerful observability tools fail if teams can’t use them effectively. Middleware reviews consistently highlight the platform’s clean, intuitive interface as a factor in successful adoption.
The dashboard design balances depth with accessibility. Users report being able to quickly pinpoint system bottlenecks, even without deep technical backgrounds. Pre-built integrations with tools like Slack and Jira further reduce onboarding friction by connecting observability data to existing workflows.
Customizable alerting based on specific KPIs allows teams to tune the platform to their operational priorities. Rather than drowning in generic alerts, engineers receive notifications aligned with the metrics that actually matter for their services.
Some users note that advanced features could be better documented, creating a steeper learning curve for less technical team members. However, the core workflow from alert to investigation to resolution receives consistently positive feedback for usability.
“Middleware provides real-time observability that’s incredibly user-friendly, even for teams without deep technical backgrounds. The UI is clean, intuitive, and data-rich, making it easy to pinpoint system or application bottlenecks.”
Professional at Self-employed
Explore Middleware’s integrations library to see how it connects with your existing tools from day one.
What the recognition signals for your evaluation
G2 recognition provides external validation, but the substance behind that recognition matters more than the badge itself. Middleware’s reviews reveal a consistent pattern: teams consolidate tools, reduce incident response time, and gain unified visibility across their infrastructure.
The platform’s strengths align with common observability pain points: tool sprawl, alert fatigue, unpredictable costs, and slow root cause analysis. Users across different organization sizes and technical contexts report similar benefits, suggesting the platform delivers reliably across environments.
Areas for continued development include expanding third-party integrations and improving dashboard customization options. These appear as consistent suggestions rather than deal-breaking limitations. The core observability capabilities receive strong endorsement.
For teams currently evaluating observability platforms, Middleware’s G2 recognition represents verified evidence that the platform performs as described. The reviews on G2 back that recognition, providing specific, actionable insight into what deployment looks like in practice.
Ready to see it for yourself? Start your free trial of Middleware, no credit card required.
End Note
Middleware earned G2 recognition because verified users documented real outcomes, not because of a marketing push. Here’s what the evidence shows:
- Unified observability replaces three to five siloed tools, eliminating tab switching and manual correlation that slow incident response.
- Native OpenTelemetry integration covers Go, Python, Java, and more, delivering standards-compliant telemetry without custom instrumentation work and reducing vendor lock-in risk.
- Transparent pricing creates measurable cost savings versus host-based alternatives, removing the perverse incentive to under-instrument growing infrastructure.
- OpsAI, Middleware’s AI SRE agent, surfaces root causes and suggests remediation paths during active incidents, proven to improve on-call productivity by over 80% internally.
- A clean, data-rich UI enables adoption across teams regardless of technical depth, with pre-built Slack and Jira integrations that fit existing workflows out of the box.
- Opportunities remain in documentation depth and dashboard customization, consistent feedback that signals product direction, not platform limitations.
For DevOps teams and SREs building their observability stack, G2 recognition is a reliable signal worth examining. The reviews behind Middleware’s recognition tell a consistent story: fewer tools, faster resolution, and infrastructure you can actually trust.
Explore Middleware: APM · Log monitoring · Infrastructure monitoring · OpsAI · Pricing



